|
Proceedings
Table of Contents

Keynote
Speakers
Invited
Cross-Cutting Themes
CODATA
2015
Physical
Science Data
Biological
Science Data
Earth
and Environmental Data
Medical
and Health Data
Behavioral
and Social Science Data
Informatics
and Technology
Data
Science
Data
Policy
Technical
Demonstrations
Large
Data Projects
Poster
Sessions
Public
Lectures
Program
at a Glance
Detailed
Program
List
of Participants
[PDF File]
(To view PDF files, you must have Adobe
Acrobat Reader.)
Conference
Sponsors
About
the CODATA 2002 Conference
|
|
Track I-C-1:
Advances in Handling Physico-Chemical Data in the Internet
Era (Part 1)
Chairs:
William Haynes and P. Linstrom, National Institute of Standards
and Technology, USA
Modern
communications and computing technology is providing new
capabilities for automated data management, distribution,
and analysis. For these activities to be successful, data
must be characterized in a manner such that all parties
will be able to locate and understand each appropriate
piece of information. This session will focus on characterization
of physico-chemical property data by looking at two related
areas: (1) the characterization of physical systems to
which data are referenced and (2) the representation of
data quality. Scientists have often assessed these quantities
in the context of the document in which the data are presented,
something automated systems cannot do. Thus, it will be
important that new data handling systems find ways to
express this information by using methods that can be
recognized and fully understood by all users of the data.
Many challenges
are presented in both of these areas:
-
Characterization
– A heat of reaction value, for example, may be
a simple scalar number but the system to which it applies
is potentially quite complex. All of the species in
the reaction must be identified, along with their phases,
stoichiometry, the presence of any additional species
or catalysts, and the temperature and pressure.
-
Representation
– Data quality must be expressed in such a manner
that all systems handling the data can deal with it
appropriately. Data quality can be considered to have
two major attributes: (a) the uncertainties assigned
to numerical property values and (b) data integrity
in the sense that the data adhere strongly to the original
source and conform to well-established database rules.
|
1.
The Handling of Crystallographic Data
Brian McMahon, International Union of Crystallography, England
The Crystallographic
Information File (CIF) was commissioned by the International
Union of Crystallography in the late 1980s to provide a common
exchange format for diffraction data and the structural models
derived therefrom. It specifically addressed the requirements
of an information exchange mechanism that would be portable,
durable, extensible and easy to manipulate, and has won widespread
acceptance as a community standard. Nowadays, CIFs are created
by diffractometer software, imported and exported from structure
solution, refinement and visualisation programs, and used as
an electronic submission format for some structural science
journals.
CIF employs simple
tag-value associations in a plain ASCII file, where the meanings
of the tags are stored in external reference files known as
data dictionaries. These dictionaries are machine-readable (in
fact conforming to the same format), and provide not only a
human-readable definition of the meaning of a tag, but also
machine-parsable directives specifying the type and range of
permitted values, contextual validity (whether an item may appear
once only or multiple times) and relationships between different
items. In many ways this is similar to the separation between
document instances and their structural descriptions (document
type definitions or DTDs) in XML, the extensible markup language
that is increasingly used for document and data handling applications.
However, while many existing XML DTDs describe rather general
aspects of document structure, the tags defined in CIF dictionaries
detail very specific pieces of information, and leave no room
for ambiguity as these items are read into and written out from
a variety of software applications.
Recognised tags
in CIF include not only subject-specific items (e.g. the edge
lengths of a crystal unit cell) but also general tags describing
the creator of the file (including address and email), its revision
history, related literature citations, and general textual commentary,
either for formal publication or as part of a laboratory notebook
record. The objective is to capture in a single file the raw
experimental data, all relevant experimental conditions, and
details of subsequent processing, interpretation and comment.
From a complete CIF, specialist databases harvest the material
they require. While such a database might be unable to store
the entire content of the source file, the IUCr encourages databases
to retain deposit copies of the source or to provide links from
database records to the source (for example as a supplement
to a published journal article).
The richness of
the tag definitions also allows automated validation of the
results reported in a CIF by checking their internal consistency.
At present validation software is built by hand from the published
descriptions of data tags, but experiments are in hand to express
the relationship between numeric tags in a fully machine-readable
and executable formulation. While the CIF format is unique to
crystallography (and a small number of related disciplines)
it has much to contribute towards the design of similar data-handling
mechanisms in other formats.
2. Development of KDB (Korea Thermophysical
Properties Databank) and Proper
Use of Data and Models in Computer Aided Process Engineering
Applications
Jeong Won Kang, CAPEC, Technical University of Denmark, Denmark
Rafiqul Gani, Technical University of Denmark, Denmark
Chul Soo Lee, Korea University, Korea
Ki-Pung Yoo, Sogang University, Korea
The physical property
data, equilibrium data and prediction models are essential parts
of process synthesis, design, optimization and operation. Although
efforts to collect and organize such data and models have been
performed for decades, the demand for data models and their
proper and efficient use are still growing. With the financial
support of MOCIE (Ministry of Commerce, Industry and Energy)
of Korea, four universities have collaborated to develop a thermophysical
properties databank and enhance their capacity on experimental
production. The databank (KDB) contains about 4000 pure components
(hydrocarbons, polymers and electrolytes) and 5000 equilibrium
data sets. Most of the data were collected along with their
accuracy of measurements and/or experimental uncertainties.
The data can be searched by a stand-alone program or via internet.
This presentation will discuss current status and features of
KDB.
In process engineering
applications, selecting proper data, selecting proper model,
regression of the model parameter and their proper uses are
the most important aspect. CAPEC( Computer Aided Process Engineering
Center, Technical University of Denmark) has been developing
programs to help the proper use of thermodynamic properties
data and prediction models for years. A stepwise procedure to
select data sets from property databases such as KDB and CAPEC-DB
, generating problem specific parameters and their proper use
through appropriate property models in process engineering problems
has been developed in CAPEC. The presentation will also highlight
the application of property model and data in specific process
engineering problems.
3.
Reliability of Uncertainty Assignments in Generating Recommended
Data from a Large Set of Experimental Physicochemical Data
Qian Dong, National Institute of Standards and Technology,
Boulder, CO, USA
Experimental (raw)
physicochemical property data are the fundamental building blocks
for generating recommended data and for developing data prediction
methods. The preparation of recommended data requires a well-designed
raw data repository with complete supporting information (metadata)
and reliable uncertainty assessments, a series of processes
involving data normalization, standardization, and statistical
analysis, as well as anomaly identification and rectification.
Since there are considerable duplicate measurements in a large
data collection, uncertainty assessments become a key factor
in selecting high quality data among related data sets. While
other information in the database can help with the selection,
the uncertainty estimates provide the most important information
concerning the quality of property data. This presentation will
focus on the assignment and assessment of uncertainty with a
large set of experimental physicochemical property data as well
as the impact of uncertainty assessments on generating recommended
data.
Uncertainties represent
a crucial data quality attribute. They are stored in the form
of a numerical value, which is interpreted as a bias for the
associated property value. The addition and subtraction of this
bias from the property defines a range of values. Without uncertainties,
numerical property values cannot be evaluated, while inappropriate
uncertainties can also be misleading. In assessing uncertainty
all potential sources of errors are propagated into the uncertainty
of the property. In this process, complete information on measurement
techniques, sample purity, uncertainty assessment by the investigator,
and investigator's experience/records, etc. is essential in
establishing uncertainties by database professionals.
Reliable provision
of uncertainties for property values in databases establishes
the basis for determination of recommended values. However,
the process of arriving at an appropriate judgment on uncertainties
is rather complex. Correct assignment of uncertainty requires
highly knowledgeable and skilled data professionals, and furthermore,
includes a subjective component. A large-scale data collection
such as TRC SOURCE makes this sophisticated task even more demanding.
A recent statistical analysis on critical constants and their
uncertainties assigned in TRC SOURCE reflected the difficulty
in assigning reliable uncertainties and also revealed a decisive
effect of uncertainties on generating recommended values. Based
on this study, a computer algorithm has been developed at NIST/TRC
to systematically evaluate uncertainty assessments.
4. Dortmund Data Bank (DDB)- Status,
Accessibility and Future Plans
Jürgen Rarey and Jürgen Gmehling, University of
Oldenburg, Germany
With a view to the
synthesis and design of separation processes, fitting and critical
examination of model parameters used for process simulation
and the development of group contribution methods 1973 a computerized
data bank for phase equilibrium data was started at the University
of Dortmund. While at the beginning mainly VLE data for non-electrolyte
mixtures (Tb > 0 °C) were considered, later
on also VLE (including compounds with Tb < 0 °C),
LLE, hE, γ∞, azeotropic, cPE,
SLE, vE, adsorption equilibrium, ... data for non-electrolyte
and electrolyte systems as well as pure component properties
were stored in a computer readable form. This data bank (Dortmund
Data Bank (DDB)) now contains nearly all worldwide available
phase equilibrium data, excess properties and pure component
properties.
To use the full
potential of this comprehensive compilation a powerful software
package was developed by DDBST GmbH (www.ddbst.de) for verifying,
storing, handling and processing the various pure component
and mixture data. Programs for the correlation and prediction
of pure component properties, phase equilibria, excess properties
as well as graphical data representation were also included.
Together with the
data from the Dortmund Data bank these programs allow to analyze
the real mixture behavior of a system of interest and to fit
reliable model parameters (gE-models, equations of
state, group contribution methods) for the synthesis and design
of chemical processes on the basis of the most actual experimental
data and estimation methods.
The talk will give
an overview on the development, structure and contents of the
DDB and will highlight certain aspects of the accessibility
and use of thermophysical data in the Internet age. Future plans
concerning the development of the DDB and the software package
DDBSP will be discussed.
|
Track I-D-1:
Data On Gas Hydrates
Chair: Fedor Kuznetsov, Inst. Inorg. Chem., Novosibirsk,
Russia
The
session will be devoted to a discussion of the status
of data on gas hydrates. It is of great interest now
in many countries to find reliable and economically
viable ways to use the huge resources stored in nature
in the form of solid gas hydrates in permafrost areas
and at the bottom of the ocean. Recovery of gas from
these deposits is an extremely complicated undertaking.
Exploration of the deposits, development of technologies
for gas recovery, conditioning and transportation, prevention
of ecological hazards all of these problems require
a great variety of different data. The session will
include presentations on general problems of data collection
and management as well as information on data activity
in this field in different countries.
|
1.
Gas hydrates in Siberian geological structures
Albert D. Duchkov, Institute of Geophysics SB RAS, Novosibirsk,
Russia
Results of prospecting
of gas hydrates accumulations in continental regions of Siberia
are discussed.
In Russia, the problem of existence of gas hydrates (GH) deposits
is usually discussed in the context of hydrate saturation of
the Cenomanian gas pool at the Messoyaha deposit in east northern
part of West Siberia. However GH were never directly observed
at the Messoyaha gas deposit during 40 years of investigations.
One more producing horizon has been recognized in the same geological
area. This horizon is related to the Cazsalin Layer of Turonian-Coniacian
age, lying above the Cenomanian deposits and having more favorable
PT- conditions for hydrates formation. Analysis of specific
features of geologic structure, temperature regime of the section,
gas composition, mineralization of formation waters, logging
data, seismic prospecting materials, and sampling suggests that
gas hydrates can exist in the Cazsalin Layer of the East Messoyakha
deposit. One of the possible directions of further study of
genesis of natural gas hydrates and estimation of the effect
of gas hydrates processes on the structure of gas deposits and
gas resources is study of the hydrocarbons accumulated in the
Cazsalin Layer of the East Messoyakha deposit with sampling
of core by a sealed thermostatically controlled corer.
The GH accumulations were found in Lake Baikal (East Siberia).
Multichannel seismic studies, performed during 1989 and 1992,
have revealed in Baikal the "bottom-simulating reflector"
(BSR), which gives an exact evidence of existence of the lower
boundary of the GH layer. It has been established that gas hydrates
are distributed in South and Central parts of Lake everywhere
in places where the water depth is more than 500 meters. Four
types of tectonic influence were revealed: 1) modern faults
shift the BSR as they do it with usual seismic boundaries; 2)
older faults shift normal reflectors, the BSR has no shifts;
3) modern faults form zones, where the BSR is destroyed; 4)
the processes that proceed within older faults situated closely
to the base of hydrated layer leads to undulations of the BSR.
The depth of lower boundary of the GH layer in Baikal ranged
from 35 to 450 m. The GH presence in the Lake Baikal sediments
has been confirmed by underwater borehole BDP-97 and special
geological investigations. The GH accumulations were found at
the surface of bottom and in sands at the depth interval 121-161
m below bottom.
2.
Gas Hydrates - Where we are now?
Yuri Makogon, Petroleum Engineering Department, Texas
A&M University, USA
Gas hydrates
were known for more than 200 years (1778 - Priestley). However,
we have been studying industrial hydrates for about 70 years.
There are more than 5000 publications related to the research
on gas hydrates. We have learned some properties of hydrates
formed in technological systems of production and transport
of gas. We know the conditions for the formation and dissociation
gas hydrates, we know the methods of removing hydrate plugs
from pipelines, and the prevention methods of hydrate formation.
Natural hydrates of gas have been intensively studied over
the past 30-40 years. Today we know the conditions of hydrate
formation in porous media in real natural conditions, we
know the regions of the world where there are hydrate deposits.
Over 120 gas hydrates deposits have been discovered with
the reserves of over 500 trillions cubic meters. The total
potential reserves of gas in hydrates is 1.5 1016 m3.
The areas of
study of gas hydrates that need to be developed include:
-
Properties of hydrates and hydrate-saturated media
-
Conditions of formation and dissociation of hydrates in
porous media
-
Effective technologies for production of gas from offshore
and permafrost hydrates
-
Optimum conditions for storage and transportation of gas
in hydrate state
-
Influence of gas hydrates on the Earth environment
3.
Data on kinetics and thermodynamics of gas hydrates, application
to calculations of phase formation
John A. Ripmeester, SIMS, NSC, Canada
Experimental data on gas hydrates are being produced at a rapid
rate, and arise from laboratory studies, field studies and industrial
laboratories, each working independently. The international
hydrate community has an increasing need to access reliable
data on the structural and physicochemical properties on hydrates
in an efficient way. The creation of an information system covering
all issues relating to hydrates is essential, as this is necessary
for the prediction of hydrate occurrences, both in natural and
industrial environments and the control of hydrate formation
and decomposition. Ultimately this will affect our ability to
predict the existence of hydrate-related hazards, to judge the
potential for hydrates to contribute to the global energy supply
as well as their possible influence on climate change.
4.
Gas Hydrates Management Program at GTI
A. Sivaraman, Gas Technology Institute, USA
Gas hydrates are
an impediment to gas flow as well as a potential energy resource.
When they form inside pipelines, hydrates can slow or completely
block gas flow, a significant problem for producers striving
to move gas from offshore wells to onshore processing facilities.
Producers, gas storage, transmission companies spend millions
of dollars each year on hydrate inhibitors and other actions
to help prevent hydrate formation, trying to balance cost, environmental
impact, efficiency and safety. Better understanding of the mechanisms
that trigger hydrate formation and dissociation could lead to
creation of more effective hydrate inhibitors.
The U.S. Department of Energy, Gas Research Institute (Currently
GTI) and U.S Geological Survey have documented the presence
of hydrates in artic Alaska, off the U.S. Atlantic and Pacific
coasts, as well as in the Gulf of Mexico and the hydrate deposits
contain as much as 320,000 Tcf of natural gas compared to the
current consumption of 22.5 Tcf per year in United States. Various
joint industry programs are focused in drilling and producing
gas from gas hydrate fields in deep waters off the coast in
US and Japan.
GTI is the premier,
industry-led natural gas research and development organization
in the United States, dedicated to meet current and future energy
and environmental challenges. At its facilities near Chicago,
Illinois, GTI has assembled state-of-the art laboratories (Laser
Imaging, Acoustics and Calorimetry) operated by an expert research
team that is uniquely equipped to investigate the mechanism
of formation and dissociation of gas hydrates; the impact of
drilling fluids, the low dosage inhibitors and anti agglomerents
on the hydrates. Recent results from the facility are presented.
5.
Computer Modeling of the Properties of Gas Hydrates - The state-of-the-art
John S. Tse, Steacie, Institute for Molecular Sciences, National
Research Council of Canada
Various theoretical
techniques for the modelling of the physical, thermodynamics
and electronic properties of gas hydrates will be reviewed.
Selected examples from recent work of the author's group will
be presented. Emphasis will be placed on the prediction of the
dynamic properties, occupancy, formation and dissociation mechanism
of gas hydrates. Perspective on using advanced simulation method
for the prediction of phase equilibria will be discussed.
6.
Natural Gas Hydrates Studies in China
Shengbo Chen and Guangmeng Guo, Institute of Geography Sciences
and Natural Resources Research, China
Natural gas hydrates
studies are very important. The CODATA Task Groups on Data on
Natural Gas Hydrates was newly approved in October 2000. In
China, gas hydrates is a potential field for studying and exploring.
The area of permafrost regions accounts for 10% of the world
permafrost, especially in the mid-latitude and high-altitude
mountainous regions in Qinghai-Tibet Plateau. The oil-gas resources
have been confirmed by exploring in the north of Tibet Plateau.
It is made clear that methane emissions and carbon dioxide uptake
by observation in Qinghai-Tibet Plateau. These evidences show
volumes of gas hydrate may be exist. In addition, extensive
sea and long shoreline make it hopeful that began to study and
explore gas hydrates. In China offshore seas, mainly in South
China Sea and East China Sea, obvious signs of hydrates have
been distinguished in seismic reflection profile, and high temperature
of seawater and high ratio of methane in fluids can be observed.
All these signs and observations indicate that it is completely
possible there exists a large amount of gas hydrates in China
offshore seas.
In 1990, the first experimental forming of gas hydrate was finished
by composing methane and water vapor in China. Subsequently,
more and more university, institute and corp. involve in gas
hydrates studies, including thermodynamics of hydrate formation/decomposition,
seismic observation and geochemical analysis. For example, the
9 bottom simulating reflection (BSR) was found in South China
Sea, and methane contents analysis by collecting sample in East
China Sea have been carried out. The information of new Earth
Observation System (EOS), including EOS-MODIS and EOS-MOPITT
is being applied to exploring gas hydrate in Qinghai-Tibet Plateau.
The land surface temperature information in the permafrost can
be retrieved by the infrared data of EOS-MODIS, and the methane
emissions and carbon dioxide uptake can also gained easily by
EOS-MOPITT. Actually, the high temperature of sea surface by
the infrared data retrieving is consistent with the distribution
of high ratio of methane in fluids in East China Sea, which
proved it is possible by using EOS information.
7.
State of CODATA project on information system on Gas Hydrates
Fedor A. Kuznetsov, Institute of Inorganic chemistry SB RAS,
Chairman of CODATA Task Group, Russia.
Previous CODATA
general assembly approved establishment of task group on Gas
Hydrates data. Most authoritative specialists in field of gas
hydrates were invited to be members of the group. They in total
represent all major field of science and technology related
to gas hydrates and most of the countries, were gas hydrates
studies attract significant attention. The group has developed
a concept and general recommendations on the structure of the
system and requirements of data.
The system thought of as a network of independent data groups,
which make their own data bases in field of their expertise.
What makes this network a distributed information system is
set of requirements for data management accepted by all the
participants. The planned system will cover information from
the following areas of science and application in relation to
gas hydrates:
-
-
-
-
Chemistry and Physics of hydrate
-
-
Kinetics of gas hydrate formation, transformation and dissociation
-
-
Technology of development of oil and gas
-
Technology of gas hydrates deposits development
-
Ecological impact of gas hydrates exploitation.
-
-
Economics of gas hydrates development, recovery, transportation
and use.
-
Use of gas hydrates in different sectors (fuel, chemical industry…)
By now more then
a hundred groups in different countries identified by now as
prospective participants of creation of the system.
Present state of the system and plans for future will be reported.
|
Track III-C-1:
Materials Databases
Chair: Huang Xinyue
|
1.
Molten Salt Database Project: Building Information and Predicting
Properties
Marcelle Gaune-Escard, Ecole Polytechnique, France
The genesis of the
Molten Salt Database, realized as early as 1967 with the publication
of the Molten Salt Handbook by George Janz is as relevant today
as it was over 30 years ago. New high-tech applications of molten
salts have emerged and the need for data is crucial for the
development of new processes (pyrochemical reprocessing of nuclear
fuel, nuclear reactors of new generation, elaboration of new
materials, new environment-friendy energetic sorces, …).
Building a world-class
critically, evaluated database is a difficult and complex process,
involving considerable time and money. Ultimately, the success
of the project depends on positive interactions between a diverse
group of people - support staff to identify and collect relevant
literature, scientists to extract and evaluate the data, database
experts to design and build the necessary data architecture
and interfaces, database reviewers to ensure that the database
is of the highest quality, and marketing staff to ensure the
widest dissemination of the database. The advent of the World
Wide Web (WWW) has provided another exciting component to this
paradigm - a global database structure that enables direct data
deposition and evaluation by the scientific community.
Also the new concepts
in engineering data information system are emerging and make
it possible to merge people, computers, databases and other
resources in ways that were simply never possible before.
Ongoing efforts in this respect will be described with the ultimate
goal of building a Virtual Molten Salt Laboratory.
These efforts are
made in parallel with our current research activities on molten
salts but also in interaction with those other related actions
on materials and engineering. For instance, it is also intended
to adapt and apply methodologies originally used for other purposes
("human genome") to the field of molten salts., as
recently demonstrated for other materials by K. Rajan at RPI,
using computational "informatics" tools.
2.
Development of Knowledge Base System Linked to Material Database
Yoshiyuki Kaji, Japan Atomic Energy Research Institute (JAERI),
Japan
Hirokazu Tsuji, Japan Atomic Energy Research Institute (JAERI),
Japan
Mitsutane Fujita and Junichi Kinugawa, National Institute for
Materials Science, Japan
Kenji Yoshida and Kazuki Shimura, Japan Science and Technology
Corporation, Japan
Shinichi Mashiko and Shunichi Miyagawa, Japan Nuclear Cycle
Development Institute, Japan
Shuichi Iwata, University of Tokyo, Japan
The distributed
material database system named 'Data-Free-Way' has been developed
by four organizations (the National Institute for Materials
Science, the Japan Atomic Energy Research Institute, the Japan
Nuclear Cycle Development Institute, and the Japan Science and
Technology Corporation) under a cooperative agreement in order
to share fresh and stimulating information as well as accumulated
information for the development of advanced nuclear materials,
for the design of structural components, etc. In the system
retrieved results are expressed as a table and/or a graph.
In order to create additional values of the system, knowledge
base system, in which knowledge extracted from the material
database is expressed, is planned to be developed for more effective
utilization of Data-Free-Way. A standard type retrieval screen
is prepared for users' convenience in Data-Free-Way. If typical
retrieved results through the standard type retrieval screen
are available, users do not need to retrieve the data under
the same condition. Moreover, if the meaning of the retrieved
results and the analyzed results are stored as knowledge, the
system becomes more beneficial for many users. As the first
step of the knowledge base development program, knowledge notes
have been made where typical retrieved results through the standard
type retrieval screen and the meaning of the retrieved results
are described by each organization. XML (eXtensible Markup Language)
has been adopted as the description method of the retrieved
results and the meaning of them. One knowledge note described
with XML is stored as one knowledge which composes the knowledge
base. Knowledge notes can be made at each stage of the data
retrieval, the display of the retrieved results, or the graph
making. A set condition at each stage can be reproduced from
the knowledge note. Storing knowledge obtained as retrieved
results are described with XML. And a knowledge note can be
displayed using XSL (eXtensible Style Language). Since this
knowledge note is described with XML, the user can easily convert
the display form of the table and the graph into the data format
which the user usually uses. Moreover, additional information
to the retrieved numerical values such as a unit can be easily
conveyed.
This paper will describe the current status of Data-Free-Way
and the description method of knowledge extracted from the material
database with XML.
3.
Activity on Materials Databases in the Society of Materials
Science, Japan
Tatsuo Sakai, Ritsumeikan University, Japan
Izuru Nishikawa, Osaka University, Japan
Atsushi Sugeta, Osaka University, Japan
Toshio Shuto, Mitsubishi Research Institute Inc., Japan
Masao Sakane, Ritsumeikan University, Japan
Tatsuo Inoue, Kyoto University Sakyo-ku, Japan
The data book, consisting of Vols.1, 2 and 3, was published
in 1982 by the Society of Materials Science, Japan (JSMS). Volumes
1 and 2 contained numerical data of fatigue strength of metallic
materials, and Vol.3 contained graphic presentations of the
data. All the data were compiled as a machine-readable database
and the database was opened to use in the research and engineering
applications. Furthermore, after collecting additional new data,
the serial data book was also published in Vols.4 and 5 in 1992
from the same society, and these data were also compiled as
the database. The CGS unit system was used in Vols.1, 2 and
3, but the SI unit system was employed in Vols.4 and 5.
In order to facilitate the useful application, both data books
were combined with each other as a fully revised version, and
a new data book of three volumes was published by Elsevier Science
B. V. and JSMS in 1996. The database was similarly revised as
a new version and it was circulated as several types of medias
such as Floppy Disc, DAT-Tape domestically in Japan. These databases
have been widely used in the engineering applications in Japan.
In accordance with the progress of information technology, requirements
to the materials database were markedly increased in the last
decade. Thus, JSMS had organized some new projects to construct
two other kinds of databases in the area of materials science.
The first one is the database on tensile and low-cycle fatigue
properties of solders. The objective materials are Sn-37Pb and
Sn-3.5Ag solders, respectively. The second one is the database
on the material characteristics such as stress-strain curves
and temperature dependence of heat conductivity, specific heat,
elongation and Young’s modulus. These databases were circulated
as CD-ROM domestically in Japan.
In the present conference, the historical scope of the database
construction in JSMS and their contents are introduced together
with some examples of their engineering applications performed
by some research groups in JSMS. Making reference to discussions
in the present conference, the authors are looking for the effective
method to circulate the JSMS databases in the worldwide scale.
4.
Role of MITS-NIMS to Development of Materials database
Y. Xu, J. Kinugawa and K. Yagi, National Institute for Materials
Science (NIMS), Japan
Material Information
Technology Station (MITS) of National Institute for Materials
Science (NIMS), established in October 2001, is aimed to be
a worldwide information center for materials science and engineering.
Our main activities include fact-data producing and publication,
literature data acquisition, and database production. We have
been continuing experiments of metal creep and fatigue for 35
years, and the data are published and distributed as NIMS Data
Sheets. Besides, from this year, we start literature data acquisition
on materials' structure and properties. Both of the fact-data
and literature data are stored and managed as databases. We
are constructing more than 10 material databases, which include
polymers, metals and alloys, nuclear materials, super conducting
materials, etc. Online services of these databases will be available
from next April.
Being aware that a simple system with only data retrieving
function can not provide enough information for material research
and industrial activities, in which not only data, but also
data related knowledge, and decision support function are needed,
we have started several new research and development projects
aiming to construct intelligent material information systems
with data integration, data analysis and decision support functions.
One of our projects is to develop a material risk information
platform. Basing upon material property databases, material
life prediction theory, and accident information databases,
this platform will provide users with material risk knowledge
as well as fact data, for the purpose of safe use and correct
selection of materials used for high risk equipment, for example,
a power plant.
Another system under construction is a decision support system
for composite material design - a composite design and property
prediction system. With this system, a virtual composite can
be composed with optional structure and component materials.
Then some basic properties such as thermal conductivity of the
composite can be evaluated according to its constitution and
the properties of constituents that stored in the databases.
|
Track III-D-1:
Physical/Chemical Data Issues
Chair: Marcelle Gaune-Escard, Ecole Polytechnique, France
|
1.
Thermodynamic Properties and Equations of State at High Energy
Densities
V. E. Fortov, Institute for High Energy Densities, Russian
Academy of Sciences, Moscow, Russia
During last century
the range of thermodynamic parameters was greatly broadened
because of rapid development of technologies. Thermodynamic
properties of matter at high pressures and temperatures are
very important for fundamental researches in the fields of nuclear
physics, astrophysics, thermodynamics of dense plasma. A number
of applications such as nuclear fusion, thermonuclear synthesis,
creation of new types of weapon, comet and meteorite hazard
etc. requires knowledge of experimental data in a wide region
of parameters.
Traditional way of studying of thermodynamic properties of substances
at high temperatures and pressures is shock-wave experiments.
During last 50 years there have been published about 15000 experimental
points on shock compression, adiabatic expansion and measurements
of sound velocity in shock compressed matter. These data are
used to determine the numerical coefficients of general functional
dependencies found from theoretical considerations in semiempirical
equations of state (EOS). In this work presented are different
semiempirical EOS models which are used for generalization of
experimental and calculated data: from simple caloric models
for organic compounds and polymer materials to complex multiphase
equations of state for metals. These EOS models are valid in
a wide range of phase diagram and describe experimental data
with good accuracy. These models are also included into the
database on shock-wave experiments with public access. The database
allows one to perform calculations of EOS for large amount of
substances and compare the results with experimental data in
graphic form via Internet by address: http://teos.ficp.ac.ru/rusbank/.
2.
Internet Chemical Directory ChIN Helps Access to Variety of
Chemical - Databases on Internet
Li Xiaoxia, Institute of Process Engineering (formerly Institute
of Chemical Metallurgy), Chinese Academy of Sciences, China
Li Guo, Hongwei Yang, Fengguang Nie, Zhangyuan Yang & Zhihong
Xu
ChIN is a comprehensive directory of Internet chemical resources
on Internet and is constructed on an information base approach
other than a merely collection of chemistry related links. The
daily maintenance of ChIN is done with the aid of ChIN-Manager,
a specific tool based on database for maintaining flexible categories,
for creating resource summary pages based on different data
models. ChIN has been widely recognized in China. ChIN has been
summarized as a site with a huge set of evaluated resources
for chemists of all disciplines by ChemDex Plus of ChemWeb.com.
ChIN has been considered also as the best Internet chemistry
resources index in China by ChemDex of University of Sheffield,
which is a well known web directory of chemistry in the world.
As chemical databases are the basic daily tools for chemists
to get information, chemical database category is one of the
most important categories in ChIN. More than 300 databases have
been indexed in ChIN, covering varies databases such as bibliographic
databases, chemical reactions databases, chemical catalogs,
databases for material safety, databases for physical properties,
databases for spectroscopy, materials databases, environmental
databases, chemists phone books and so on. There is also a subcategory
for selected news on the progress of major commercial chemical
databases. There is a summary page for each database indexed
in ChIN, summary pages for related databases that may classified
into different subcategories are cross linked. Up to now, among
the chemical databases indexed within ChIN, more than 70 databases
can be freely accessible and over 20 databases provide free
searching. The total successful requests to ChIN is over 2.5
millions since 1998 and about half are from oversea visits.
About 15% requests go to indexing pages of chemical databases
in ChIN.
References
1. ChIN Page, http://www.chinweb.com.cn/, the former URL is
http://chin.icm.ac.cn/
2. Xiaoxia Li, Li Guo, Suhua Huang, Zonghong Liu, Zhangyuan
Yang, “Database Approach in Indexing Internet Chemical
Resources”, World Chemistry Congress, Chemistry by Computer,
OB28, Brisbane, 1 - 6 July 2001
3.
Graph-Theoretical Concepts and Physicochemical Data
Lionello Pogliani, Dipartimento di Chimica, Università
della Calabria, Italy
The molecular polarizabilities of fifty-four organic derivatives
have been optimally modeled, the induced dipole moment of another
set of sixty-eight organic compounds, have, instead, been less
optimally modeled. The modeling was performed by the aid of
particular descriptors that have been derived by the aid of
graph theoretical concepts. Till recently the starting point
of these modeling strategies was the hydrogen-suppressed chemical
graph and pseudograph of a molecule, which for second row atoms
worked quite fine. For each type of graph or pseudograph an
adjacency matrix can be written. Actually the pseudograph matrix
is enough to represent mathematically either a graph or a pseudograph
of a hydrogen-suppressed molecule, as it encodes not only information
on single connections but also on multiple connections and self-connections,
which mimic multiple bonds and non-bonding electrons. From these
matrices specific theoretical graph-structural invariants can
be derived, among which the molecular connectivity indices and
pseudoindices. For molecules with higher-row atoms, i.e., atoms
with n>2, the graph representation alone was insufficient
to derive a specific invariant and use was done of atomic concepts,
as there was no other way to encode the contribution of the
inner-core electrons of higher-row atoms. Recently, and for
the first time, inner-core electrons have been successfully
'graph' encoded by the aid of complete odd-graphs, Kp, and of
the corresponding adjacency Kp-pseudograph matrix. The use of
complete odd-graphs to derive graph-theoretical invariants allowed
an optimal modeling of the molecular polarizabilities and a
not too bad modeling of the induced dipole moment of organic
derivatives of better or similar quality than the modeling achieved
by MM3 calculations. Other types of 'non-pure' graph-theoretical
invariants achieved less satisfactory modelings.
4.
Progress in the Development of Combustion Kinetics Databases
for Liquid Fuels
Wing Tsang, National Institute of Standards and Technology,
USA
This presentation is concerned with the development of a database
for the simulation of gas phase combustion. In recent years
simulation have become an important tool in technology. The
key for effective simulations is a reliable database of information
that form the essential inputs. In the area of combustion, the
complexity of the process has made necessary the building of
large databases. This has been hindered by the fact that gas
kinetics, the disciplinary field responsible for generating
the database is still a research area. Thus there has been a
need for constant upgrading. Even more serious is that most
combustion is carried out with liquid fuels which are complex
mixtures of intermediate sized hydrocarbons. Normal alkanes
are important components and they may contain ten or more carbons.
There has been considerable recent work on the oxidation of
various fuels. For one or two carbon fuels there is a state
of the art database GRIMECH. There are also databases that describe
the formation of PAHs and soot. A complete database should contain
sufficient information that will cover the oxidation and pyrolysis
reactions leading to soot formation. It should also start with
some important components of liquid fuel. We have now started
work in this direction using heptane as our prototypical liquid
fuel. The aim is to develop the kinetics sufficiently so that
they can be interfaced with the existing databases mentioned
earlier.
The need is for a database specifying the thermal cracking reactions
of the fuel. These can be classified as bond breaking of the
fuel, decomposition of the radicals formed from bond breaking
and/or radical attack, decomposition of olefins, the first stable
product from radical decomposition, and finally the decomposition
of the olefinic radicals. This will define the nature of the
competition between oxidation and cracking and the small unsaturated
species that are starting point for PAH formation and soot models.
Among the four classes of reactions, processes beginning with
stable compounds are in satisfactory conditions in the sense
of the availability of experimental data or methods for estimation.
The technically difficult problem is the quantitative specification
of the decomposition modes of the radicals. This is due to the
fact that larger alkyl radicals can also isomerize. Thus for
many cases it is necessary to consider the decomposition modes
of all the isomerization products simultaneously. Furthermore
due to their low reaction thresholds energy transfer effects
must be considered. This means that reaction rates are pressure
as well as temperature dependent. We will describe how this
problem has been solved in the C5-C7 radicals. Finally we show
how the present results lay the basis for the extension of the
database too much more complex fuel mixtures.
5.
Database of Geochemical Kinetics of Minerals and Rocks
Ronghua Zhang, Shumin Hu, Xuetong Zhang and Yong Wang
Open Research Laboratory of Geochemical Kinetics, Chinese Academy
of Geological Sciences, Institute of Mineral Resources, China
Data of reaction
rates of minerals and rocks in waters at high temperatures T
and high pressures P are important in understanding the water
-rock interactions in lithosphere, and in dealing with the pollution
of ground water and deep buried nuclear wastes. Reaction rates
have been measured experimentally in the T range 25 to 300 °C
and at various pressures. A few kinetic experiments of the mineral
dissolution were performed at T above 300 °C and P higher
than 22 MPa. Experiments were usually carried out using flow
reactors. As operating a continuous stirred tank reactor CSTR
reactor, steady state dissolution rates r (mol.sec-1m-2)
were computed from the measured solution composition using
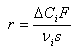
where
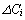
stands for the molar
concentration difference between the inlet and outlet of the
ith species in solution, F represents the fluid mass
flow rate, vi refers to the stoichiometric
content of i in mineral, s is the total mineral surface
in the reactor (m2). As operating a flowthrough packed
bed reactor PBR, mineral particles were put inside the vertical
vessel. Within the PBR, a transient material balance in a column
at length Z gives:
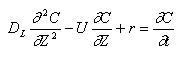
This model characterizes
mass transfer in the axial direction in terms of an effective
longitudinal diffusivity DL that is superimposed
on the plug flow velocity U. The length Z and
U have been known. As measured the residence time distribution
function of the flow system, we can figure out the DL.
If the boundary condition and initial condition are well known,
then, the dissolution rate of the mineral is derived from the
following mass balance expression for the concentration of the
ith solute in a reactor cell:
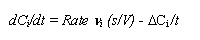
where
Ci is the concentration of ith species, t
is the average residence time, and V is the solution volume
in the pressure vessel (ml).
Recently, we measured a lot of mineral dissolution rates (carbonate,
fluorite, albite, zeolite, actinolite etc.) in aqueous solutions
at high T and P above the water critical point, and found the
fluctuation of reaction rates occurs as crossing the critical
point. And also we collect reaction rate data in the literature.
We performed the geochemical kinetics data base. It includes
r (rate law, rate constant k, activation energy
Ea, chemical affinity A etc.), the
surface nature (s, surface modification… ), t (contact
time, accumulation time… ), mineral characters (composition,
structure, occurrence, etc.), reaction system, hydrodynamic
and physicochemical conditions, analytical method and equipment.
The rate law is:
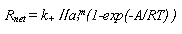
where
Rnet is the net rate of reaction, k+
is the rate constant of the forward reaction, ai
is the activity of species i in the rate determining reaction
raised to some power m. Others are included, e.g., incongruent
dissolution, non-linear dissolution rate, non-linear dynamics
in the reaction system (if happened). This data base will also
provide simulation models in predicting the water/rock interaction
in nature.
|
Track IV-A-1:
Current Trends and Challenges in Development of Engineering
Materials Databases
Chair: Aleksandr Jovanovic, MPA Stuttgart, Germany
This session
will provide an overview of some major issues related
to performance, service and use of engineering materials
databases, from the viewpoint of users and developers.
The aspects of interest are, e.g., use of rapid prototyping,
usability (ie. user friendliness), availability (stand-alone,
LAN, Internet/Intranet), safety, reliability, etc. In
particular, the issue of integrated, distributed and web-oriented
databases and data warehouses will be considered. Most
of these aspects require different solutions so the optimum
one must be found in each case.
Related issues to be addressed include:
1. Measuring performance, service and use of software
databases and data warehouses;
2. Internet and intranet databases, including implications
of the technology for the 'contents' (i.e. materials data)
and for the users;
3. Data vs. information vs. knowledge in engineering materials
databases and data warehouses - including e.g. databases
of case histories, documentation, etc.;
4. Integrated data assessment for production of higher
level information - e.g. automatic definition of material
laws based, e.g., on stored materials data and conventional
statistics;
5. Use of intelligent methods (neural networks, machine
learning, case-based reasoning, fuzzy clustering, etc.);
6. Data consistency, quality/reliability, quality assurance,
certification etc. in distributed systems;
7. Future trends.
Practical
applications of interest would be: large materials databases,
European and international engineering materials databases,
intelligent databases, corrosion/fatigue/creep databases,
material testing databases, databases of certified materials
data, Internet databases, materials databases in technology
transfer, etc.
|
1.
Development of a Large System of Clustered Engineering Databases
for Risk-Based Life Management
A. S. Jovanovic, MPA Stuttgart
The paper describes the development of complex databases system
comprising currently more than 30 single databases containing
data needed for the risk-based life management of components
in industrial plants. The system provides basis for the development
of a new European guideline in the area of risk-based life management
(RBLM), inspection (RBI) and maintenance (RBIM). Full-scale
application of the concepts proposed by the guideline is essentially
possible only if the issue of maximum use of available data
(and consequent minimization of the need to acquire further
data!), and only a modern, comprehensive, but flexible database
system can provide the required solution.
The database cluster is organized as a data warehouse satisfying
the needs to: (a) work in highly distributed environment, both
on the developers' and on the users' end; (b) work with constantly
changing database structures, updated/changed at the level of
the database administrator (not developer!); (c) share common
tolls and tasks across all the databases (e.g. graphics, statistical
evaluation, application of data mining tools, etc.); (d) assure
linking and possible integration of existing databases of older
generation; (e) assure transportability of the system over a
wide range of operating systems.
The paper also shows how the principles of RBLM are practically
applied in a European power plant, including the implementation
aspects in the "non-ideal situation" (lack of data,
uncertainties, need to combine experts' opinions with results
of engineering analysis, etc.).
2.
Open Corrosion Expertise Access Network
W.F. Bogaerts, University of Leuven - Materials Information
Processing & Corrosion
Engineering Labs, Belgium
H.A. Arents, Information Architects group, Flemish Regional
Government, Belgium
J.H. Zheng, University of Leuven - Materials Information Processing
& Corrosion
Engineering Labs, Belgium
J. Hubrecht, University of Leuven - Materials Information Processing
& Corrosion
Engineering Labs, Belgium
R. Cottis, UMIST - Corrosion and Protection Centre, UK
The paper will describe concepts and results from the European
Commission supported "OCEAN" project (Open Corrosion
Expertise Network), of which the first phase is about to be
finalized during 2002. The objective of this project is the
design and implementation of an open, extensible system for
providing access to existing corrosion information. This will
be achieved through a network of interested data providers,
users and developers. Where available, existing standards and
technologies will be used, with the partners developing informatics
and commercial protocols to allow users single-point access
to distributed data collections.
One of the major difficulties of corrosion engineering is the
multi-dimensional nature of the corrosion problem. A very large
number of alloys are available, and these may then be exposed
to an almost infinite range of environments. Thus, although
many thousands of corrosion tests have been performed and numerous
papers published, it remains difficult for the individual corrosion
engineer to bring together the information that is relevant
to a specific situation. To some extent this problem has been
tackled by centralized collections of corrosion data and abstracts.
However, these are limited to published information, and tend
to be rather inaccessible to potential users. The latter problem
relates partly to the dedicated user interfaces that are typically
used with these data collections, and partly to the commercial
necessities of ensuring a reasonable return for the information
providers.
The OCEAN project aims to overcome these limitations through
the development of open protocols for locating, paying for,
and obtaining corrosion information. In this context 'information'
is used very generally, and the OCEAN system is intended to
cover all sources of corrosion information including large centralized
data collections, individual data collections from research
projects, human expertise distilled into books and expert systems,
computer-assisted learning texts, multimedia resources and access
to human experts. The nominated partners in the project include
representatives of several categories of information providers
and users, with interest groups allowing additional organizations
to participate in the project. It is a specific objective of
the project that OCEAN will be open; open to all information
providers to offer information, and open to all data users to
obtain information. At the same time the commercial value of
information will be recognized through commercial protocols,
and partners in the project have particular expertise in funds
transfer and electronic information systems (publishing).
The detailed specification of the OCEAN system has been one
of the first tasks of the project, and the approach is based
on World-Wide Web technology. The core of the OCEAN system will
be an intelligent database and re-director that accepts queries
in a standard form and then directs them to OCEAN data sources
that are registered as having information that may be relevant
to the query. The data sources respond with the data requested
(or a null return) to the originator of the query. For the initial
phase of the project a simple query engine is used to construct
correctly formatted queries from user input, and to assemble
a single response from the returns from data sources. However,
it will also be possible for users to issue queries directly
to the OCEAN re-director, or for alternative query engines to
be used. This will allow more intelligent front-ends to be developed
in due course to support less expert users, or to act as software
agents for experts.
3.
Use of Database Technology for Saving and Rescuing of Perishing
Engineering Data and Information In Eastern Europe
L. Tóth,
Bay Zoltán Institute for Logistics and Production Systems
One of the driving forces in the development of engineering
science are relating to the failures took place in different
engineering areas. That is why the results of the failure analysis
are representing a high value of worth. Due to the development
of the information technology these "local worthies"
could become a tool for general access. It is obvious that the
results of failure analysis contains always that information
which are related to that staff where the case took place, but
they contains also information for general using, which support
the "thumb rule" of "learning from failures".
Relating to the Central and Eastern European countries many
"engineering data" (including the material data and
failure case studies as well) represents only the "local
worth". It is caused by minimum two facts. One of them
is relating to the later application of the information technology
tools for saving and rescuing of perishing engineering data
and information, the other is relating to the attitude of the
engineering communities in these countries. Generally it can
be said that the responsible specialists for the failure case
studies are belonging to the middle or aged generation having
the attitudes of the 1965-75 year's of these countries. It means
that this generation is not familiar with the possibilities
of information technology and the failure cases are regarded
as "internal business" for them. Having the new generation's
ability to the modern information technology tools these obstacles
can be overcome. The best solution seems to be the creation
of the Internet technology based national failure case
studies warehouses. This database contains on the one
hand the open and general information about the failure case
studies and the other hand the "teaching aids"
related to different type of failures including the methodological
procedures of examination of the failures. Having the national
case studies databases they can be joined into the network.
It can only be effective way to realise it if minimum two criteria
are fulfilled. One of them is relating to the unified database
structure, the other is to the national language. The uniform
database structure and the pilot system have to be developed
by using "centralised support" (EU R&D support
in Europe, or the support of the insurance companies, etc.).
A Hungarian initiative will be presented which contains pp.
400 failure case studies.
4.
The Background and Development of MatML, a Markup Language for
Materials Property Data
E.F. Begley and Charles Sturrock, National Institute of Standards
and Technology, USA
MatML is an extensible markup language (XML) for the management
and exchange of materials property data. Launched in October
1999 and coordinated by the National Institute of Standards
and Technology, an agency of the U.S. Department of Commerce,
the MatML project has drawn upon the expertise of a cross-section
of the international materials community including private industry,
government laboratories, universities, standards organizations,
and professional societies. The background and development of
MatML will be described and will include a discussion of its
features and its relationship to other scientific markup languages.
|
Track IV-B-1:
Toward Interoperable Materials Data Systems
Chair: Yoshio Monma, Kochi University of Technology, Japan
There has
been growing concern for the interoperability of factual
databases in the materials database community. In order
to have interoperability in the heterogeneous environment
of the Internet/Intranet, we need a mechanism for sharing
materials information that is not dependent upon computer
systems and networking. Currently, the idea of using XML-DTD
for the description of materials data is welcomed internationally.
Two major activities may be identified: MatML in USA and
Europe and NMC's (New Material Center) XML-DTD in Japan.
Using XML/Java which supposedly allow platform independence
on computer systems in development and operation, some
advanced materials databases have achieved success toward
being truly interoperable.
This session
is intended to be a natural sequel to the June 2001 MatML
Workshop held at NIST (USA) and cosponsored by the VAMAS
TWA 10 (Computerized Materials Data). In this Session
we want to exchange ideas and experiences in building
and using materials data systems intended to be interoperable
in the WWW environment.
|
1.
Requirements for Access to Technical Data -- An Industrial Perspective
Timothy M. King, LSC Group, Tamworth, UK
The ultimate objective
of any collaborative venture is to share understanding. Such
collaboration is the fundamental basis for all social activity.
The modern-day challenge is to collaborate across the globe
in an environment where change is an ever-increasing factor.
The digital information revolution both fuels and offers to
alleviate this challenge. However, the "Tower of Babel"
remains a highly relevant parable.
Integration of computer
systems is a multi-level problem. While integration is increasingly
available across the foundation levels of hardware, software,
user access and data, semantic integration is rarely on the
basis of an explicit, agreed information model. Such models
control the representation of data.
XML is now a major
tool in the kit of system integrators. In order to control the
content of an XML file, the necessary information model is either
a DTD (Document Type Definition) or, increasingly, an XML Schema.
Organisations are generating large numbers of different DTDs
and XML Schemas to address the needs of individual projects.
Creating information
models for integration purposes causes a great deal of pain
as different organisations meet to agree and define the terminology
and required information capability. The XML community is new
to this challenge where as the ISO sub-committee TC184/SC4 <http://www.tc184-sc4.org/>
has been working for almost twenty years to create (currently)
six standards, including ISO 10303 ("Product data representation
and exchange" or "STEP").
The ISO/TC184/SC4
family of information standards addresses a wide range of industrial
requirements. Mature parts of the standards have delivered real
business benefits to various different projects. Some challenges
remain in respect of such information standards: deployment
in conjunction with project management requirements; facilitation
of concurrent systems engineering; adoption by Small to Medium
Enterprises; security; intellectual property rights; legacy
systems; and integration of multiple sources. Such requirements
remain the barrier between the sources of high quality scientific
and technical data and the exploitation of such data within
industry.
The WWW and other
communities have recognised that XML as a single prevalent representation
format is not sufficient and a current hot topic is ontologies.
Potentially, ontologies offer a different route to integration
where unified definitions across the integration levels offer
the basis for automated analysis and creation of integration
solutions. However, in the short term, "ontology"
is a label that is in use in too many different guises and projects
such as the Standard Upper Ontology <http://suo.ieee.org/>
will require further development before industry is able to
effectively exploit the potential power of ontologies.
2. The Platform System for Federation
of Materials' Data by Use of XML
Toshio SHUTO, Yutaka OYATSU, Kohmei HALADA, and Hiroshi YOSHIZU
Mitsubishi Research Institute, Inc., Japan
For improvement
of materials database as an intelligent foundation, many databases
have been developed from wide ranges of materials. However,
most of them are built independently for each field of research
and are just as a numerical value fact data. In reality very
few are realized as a full-scale utilizable database retrieval
system. Regarding material database or material data as common
property, easy performance of sharing or mutual use of material
database is requested along with utilization of non-material
specialized field. To respond to this demand, a prototype of
platform system to avail mutual use across boundaries in the
field of material database was developed.
3.
XML data-description for data-sharing of material databases
Kohmei Halada, Director of Ecomaterials Center, National Institute
for Materials Science, Japan
Hiroshi Yoshizu, Ecomaterilas Center, National Institute for
Materials Science, Japan
Toshio Shuto, Science and Technology Research Division, Mitsubishi
Research Institute, Japan
Yoshio Monma, Kochi University of Technology, Japan
The activity of VAMAS , an international collaboration of pre-standardization
of advanced material based on the agreement of Versailles summit,
on XML-based data-description for data-sharing of material-database
is introduced. The description consists of Kernel and Modules
of each field of materials properties. The Kernel is developed
by NIST, USA. The description of Modules are prepared by NMC,
Japan and JRC, EU.
The background of the collaboration is followings. Databases
of materials data are widely distributed all over the world.
However, the common procedure to retrieve and use the data from
the distributed database does not exist. For individual databases,
guidelines and standardizations have been prepared such as ASTM
E49 especially for materials data. In today's computerized era,
further development of common or standardized procedures for
the data exchange system from the viewpoint of the common platform,
on which data can be treated without the regard to the structure
of the original database, is required. The objectives of this
activity is to clarify the prerequisite for the generic platform
for electrical data-sharing systems of materials data. In order
to promote the data-sharing system from multi-resources of materials
data where each database has its own inherent structure, it
is required to prepare the common basis to retrieve, refer,
link and utilize the data among them with electrical exchange.
Now the project finished the Phase 0: feasibility study on the
electrical data-sharing platform of distributed materials data,
and goes into Phase I: Implementations. In the Implementation's
phase, trial and testing the prototype of DTD* template for
existing database are subjected. (*DTD is written on the assumption
of XML chosen as the result of Phase 0) - creation of prototype
of DTD for several existing databases
- documentation
of DTD from pre-standardized database structure such as MatML
- comparison and
testing with retrieval
- clarification
of the requisite of the generic DTD structure for material
data
By developing this
data-sharing system, various properties of materials which stored
in different databases can be linked on the generic platform
with the standardized template, in order to use for the life-cycle
design of products from comprehensive approaches such as DfE
(Design for Environment), DfS (Design for Safety), etc., used
in industry.
4.
A Prototyping of Interoperable System for Data Evaluation of
Creep and
Fatigue Data
Tetsuya Tsujikami,
Faculty of Science and Engineering, Ryukoku University, Japan
Hiroshi Fujiwara, Dept. of Environmental Systems Engineering,
Kochi University of Technology, Japan
Yoshio Monma, Dept. of Environmental Systems Engineering,
Kochi University of Technology, Japan
Takeshi Horikawa, Professor and Vice President, Ryukoku University,
Japan
From early stage
of the computerization , creep and fatigue data have been
stored in computers. So far many materials databases have
been built in this area. And a number of mumerical/statistical
procedures for the curve fitting for creep and fatigue have
been proposed. But none of them are still interoperable. Materials
data systems in the era of the Internet should have the interoperability
for not only the factual data but also for data evaluation
modules.
Analysis of the local data in remote computers and the verification
of data evaluation methods with remote data were once considered
very difficult because of the lack in the interoperability.
We need two aspects the interoperability here: the description
of materials data and mumerical/statistical procedures to
fit the equations that show the materials properties. Under
the current trend a natural choice is to use the data entities
by an XML-DTD and data evaluation software written as the
Java applet/servlet. On the basis of an XML-DTD developed
at the New Materials Center, we have developed two materials
data systems for creep and fatigue data that can be accessible
via the Internet. As a prototyping we implemented a few data
evaluation models for creep and fatigue. But it would be easy
to add models. We also compared the difference in the performance
between the two types of implementations: applet and servlet,
because some of the data evaluation models require nonlinear
iterative computation. A demonstration will be given in the
presentation.
|
Track IV-B-6:
Advances in Handling Physico-Chemical Data in the Internet
Era (Part 2)
Chairs:
William Haynes and Peter Linstrom, National Institute
of Standards and Technology, USA
Modern
communications and computing technology is providing
new capabilities for automated data management, distribution,
and analysis. For these activities to be successful,
data must be characterized in a manner such that all
parties will be able to locate and understand each appropriate
piece of information. This session will focus on characterization
of physico-chemical property data by looking at two
related areas: (1) the characterization of physical
systems to which data are referenced and (2) the representation
of data quality. Scientists have often assessed these
quantities in the context of the document in which the
data are presented, something automated systems cannot
do. Thus, it will be important that new data handling
systems find ways to express this information by using
methods that can be recognized and fully understood
by all users of the data.
Many challenges
are presented in both of these areas:
-
Characterization
– A heat of reaction value, for example, may
be a simple scalar number but the system to which
it applies is potentially quite complex. All of the
species in the reaction must be identified, along
with their phases, stoichiometry, the presence of
any additional species or catalysts, and the temperature
and pressure.
-
Representation
– Data quality must be expressed in such a manner
that all systems handling the data can deal with it
appropriately. Data quality can be considered to have
two major attributes: (a) the uncertainties assigned
to numerical property values and (b) data integrity
in the sense that the data adhere strongly to the
original source and conform to well-established database
rules.
|
1.
Materials Data on the Internet
J. H. Westbrook, Brookline Technologies, NY, USA
The availability
of the Internet has provided unprecedented opportunities
for both data compilers and users. With respect to
materials data we will explore:
-
How do we know what is available?
-
How can data be accessed, interpreted, exchanged?
-
What novel modes of presentation are now available?
-
What organizations are active in this field and
what are their programs?
-
Professional (e.g. ASM, ASTM, NIST, NIMS, VAMAS,
W3C, ...)
-
Commercial (e.g. MatWeb, MDI, CES Materials
Data, Pauling File, MasterMiner, MSC.Mvision,
IDES, ...)
-
What improvements are needed?
-
Where do we go from here and how?
Examples
will be illustrated of specific materials databases
available on the Internet from a variety of materials
data fields:
-
Fundamental data (e.g. elements from the Periodic
Table, phase diagrams, crystal structures, diffusion
constants, ...)
-
Engineering design properties
-
-
While
there is no question that large and widely varied
bodies of data are accessible on the Internet, significant
improvements are needed promptly, or else prospective
users will become so disillusioned that they abandon
electronic access for data. Among the problems that
need
to be addressed are:
-
A well-structured on-line directory to reliable
data sources should be built
-
Persons or organizations posting data need be encouraged
to include detailed instructions for searching for
and retrieving data (a title and the URL of the
homepage are not usually sufficient)
-
Any on-line data site must make clear the provenance
of the data shown
-
Any data shown should be accompanied by full metadata
for both the material whose properties are shown
and for the property data themselves
2.
Physicochemical data in Landolt-Börnstein Online
R. Poerschke, Springer-Verlag, Berlin, Germany
Nearly 120 years
ago the data collection Landolt Börnstein was founded
in the field of Physical chemistry. The broad scope of this
expert data collection in various fields ranging from Elementary
Particle Physics to Technology and the strong increase in
the number of primary articles forced a transition to the
open New series. New volumes are planned according to the
development of new fields in science and technology, whereas
the former 1th to 6th edition were planned as a closed edition.
Since 1996 CD-ROMs
are produced in parallel to the printed volumes. In the year
2000 Landolt Boernstein offered free access to all volumes
published until 1990. This prerelease was used heavily by
the 10.000 registered testusers, more than two million pages
were downloaded in a short period. An electronic user survey
showed, that more than 80% of the users wanted to have a full
electronic version of LB at their working place.
End of 2001 the
complete Landolt-Börnstein collection went online. A
fulltext search engine allows searches for substances and
properties within all 300 LB volumes, i.e. 150.000 pages and
25.000 documents. The search can be limited to a group of
Landolt-Boernstein. Specific search is possible for the fields
authors, document titles and tables of contents. Simultaneous
search in LB and all Springer journals is possible. Users
can get automatic alerting information according to their
profile of interest.
Physico chemical
data are collected systematically by specialists in the field
and various databases were built up. LB has excellent cooperation
with several database centers. First of all they provide the
raw data, which are then used by authors inside or outside
of the institutions to prepare selected, evaluated and recommended
data for the printed version of Landolt-Börnstein. For
the electronic version additional data and references can
be included. All of the material is double checked by scientists
and their assistants in the Landolt-Börnstein editorial
office.
Examples of physicochemical
data are presented:
1) Thermodynamic
data of pure substances and their mixtures: cooperation with
TRC/NIST in the USA and SGTE in Europe.
2) Liquid crystals
database LIQCRYST, Scidex. Development of a specific graphical
structure search tool for organic substances. Of course search
for CAS registry numbers molecular formula, chemical names
etc. is included. For a given substance the search yields
a dynamical combination of a variety of physical properties,
e.g. NMR, NQR and density data.
3) High quality
phase equilibrium data, i.e. phase diagrams, crystallographic
and other thermodynamic data in a simple to use periodic table
system.
3.
Expressing Measurements and Chemical Systems for Physical
Property Data
Peter Linstrom, National Institute of Standards and Technology,
Gaithersburg, MD, USA
Physical property
data are typically associated with a measurement of a particular
chemical system in a particular state. In order for such data
to be effectively utilized, both the measurement and the system
must be appropriately documented. In the scientific literature,
this information is often presented in great detail, while
in electronic databases it is often reduced to a minimal form.
For example, a scientific paper may discuss the presence or
absence of impurities in a reagent, while the entry in an
electronic database may simply refer to the reagent as a pure
compound. For many applications such an approach is reasonable,
but for others it may limit the uses to which the database
can be applied.
A common response
to criticisms that electronic databases lack this sort of
information is to note that researchers can always refer to
the original literature from which the data was abstracted.
While it may not be possible to match the detail of the original
literature, providing richer information in this area could
provide several advantages for researchers using electronic
databases. If a researcher searches a database and finds three
values for a property have been measured, with two measurements
being quite close to each other, the researcher may conclude
that the value lies near the two measurements, discarding
the third. However, if the researcher is provided with information
that indicates that the third measurement was made by a more
reliable method, this value may be chosen instead.
A major obstacle
to providing such information in electronic form is that such
work requires a grammar capable of expressing such information.
Since this sort of information is not always recorded, such
a grammar must allow for the ability to state that such information
is unknown or only known to a limited extent.
This talk will
discuss some possible approaches to improving the manner in
which chemical systems and measurements are expressed in electronic
form. It will include examples of problems encountered in
the development in the NIST Chemistry WebBook, a web site
which contains physical property data compiled from several
databases.
|


