Henda van der Berg,
National Research Foundation, Nexus Database System, PO Box 2600, Pretoria 0001,
South Africa.
E-mail: jhmvdberg@nrf.ac.za and
URL: http://www.nrf.ac.za/nexus
The global information society
The Internet presents an opportunity to researchers and research institutions in Africa to contribute to the development of the content of the global information society. The benefits of contributing to global information are many and include the following: (Chisenga,1999).Furthermore, Bergdahl (1989) posits that information has become such a precious resource that the fate of modern nations in all essentials is connected with their capacity to develop and exploit it. He further predicts that in future, countries that do not develop this capacity will be left behind in their cultural, scientific and economic development. Apart from suffering from dependence on others, such countries will neither be partners in the global production of information nor will they contribute meaningfully to the common future of civilization (Nwalo, 2000).
CODATA (ICSU) is committed to
playing an important role in the global production of information, as is clearly
formulated in its general objectives and can be seen to underpin its four primary
activities. The following three goals can be highlighted:
The primary activities of CODATA which support these goals are:
It is obviously important to capitalise on the investments already made in research by creating better mechanisms to evaluate, store, retrieve and disseminate Social Science and S&T data in Africa.
It is essential to concentrate on what is necessary for co-operation in Africa in order to supply information about sources of reliable Social Science and S&T data.
The various routes which may be followed in creating sources of reliable Social Science and S&T data for a resource discovery service are the following:
The various routes available regarding a resource discovery service may be discussed in terms of content of data, format, standards, and software/hardware requirements.
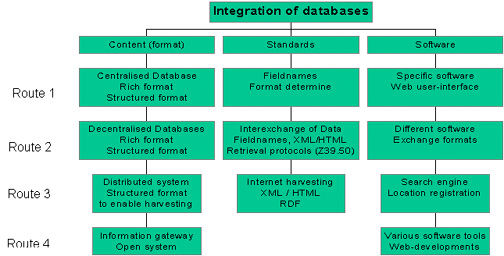
The decision on the format and standards to be used is critical, to ensure inter-operability between decentralised databases as well as for co-operative projects pertaining to central databases.
The content of a source is described by using metadata. Metadata is defined as structured data about data. The purpose of metadata is to describe the structure of data and, more importantly, to capture any additional properties that may characterise it. For instance, the URL of survey data is one such property. When referring to the Internet, metadata also means “machine understandable information”. It stands to reason that there are various types of metadata, because each repository or databank reflects its own specific data with different requirements and priorities. The review of the DESIRE project, available on the Internet at http://www.ukoln.ac.uk/metadata/desire/overview/, divides metadata formats into three categories: simple, rich and structured.
Simple formats are proprietary and based on full-text-indexing. Currently, this data is created by the web crawlers, e.g. Lycos, Altavista, Yahoo, etc. These are very easy to use, but very weak for information retrieval purposes because they do not support searching by fields.
The Desire Project (1997) describes
the various formats under a number of standard headings.
The Dublin Core (DC) is a metadata element set intended to facilitate the finding of electronic resources, and was originally conceived for author-generated descriptions of Web resources. In this presentation, I shall only indicate certain aspects of DC as an example of a format used to describe the content of a source.
The 15 Dublin Core elements have been divided into three classes (content, intellectual property and instantiation) in the following way:
|
Content |
Intellectual property |
Instantiation |
Title |
Creator |
Date |
Subject |
Publisher |
Type |
Description |
Contributor |
Format |
Source |
Rights |
Identifier |
Language |
||
Relation |
||
Coverage |
These 15 elements will remain standard, and no additions will be made except for qualifiers. The next step in Dublin Core standardisation will be the specification of the core qualifiers of the 15 Dublin Core elements.
It is, therefore, essential to establish the content of a source needed for a resource discovery service to S&T data users. Only after this has been done, may one investigate appropriate formats and standards.
Standards (Syntax)
The structure of the central
database will be determined by the content format of the data and fieldnames.
In addition, properties will be developed according to content.
An example is the Nexus Database System, which has developed an integrated research communication system, consisting of a current and completed research projects database, a database for fields of expertise and contact details of scientists in South Africa; and a research organizations database. Hypertext links between researchers, projects and organizations facilitate research communication and co-operation. <http://www.nrf.ac.za/nexus/>
The decentralised database route requires the inter-exchange of data, and may include
which are essential for co-operation.
In the first place, however, the various data owners have to agree to supply exchange formats in order to create a central database via report formats or by using the same syntax standards.
Alternatively, a decision might
be taken to use a retrieval protocol like ANSI/NISO Z39.50, the American National
Standard. Z39.50 is a computer-to-computer communications protocol designed
to support information searching and retrieval in a distributed network
environment or via decentralised databases. For example, a user physically based
in Cape Town, may use Z39.50 to query five totally different databases containing
information on archaeology at locations throughout the world. These databases
describe different data types according to various formats and are driven by
different database management software and run on a variety of hardware platforms.
Based on the client/server architecture and operating over the Internet, the
Z39.50 protocol is supporting an increasing number of software applications.
A more recent development which has already been implemented, is the distributed systems approach, which enables the harvesting of information from the Internet in an ‘intelligent’ way. The current search engines for the Internet do not answer to the need for relevant information, as more ‘intelligence’ is needed, but more intelligence requires a better structuring of information via XML, HTML and RDF. Thus, powerful syntax standards are necessary because data has to be not only machine readable, but also machine understandable. Thus, only with the help of meta-information can data be interpreted and turned into information and knowledge; and only with the support of descriptive meta-information and standard syntax can data be put to multiple uses on the Internet.
For example, a specific format like the Dublin Core may be embedded (encoded) in HTML for the Web, using a META tag and LINK tag.
XML (Extensible Markup Language) is another standard, but is currently not widely used. Once standardized, however, XML in conjunction with the Resource Description Framework (RDF), promises a significantly more expressive way of encoding metadata (Hakala, 2000).
Various services have implemented distributed systems for the harvesting of information from the Internet. SAFARI is a very successful information service which has implemented a distributed system for the dissemination and co-ordination of information on Swedish academic research. The purpose of the system is to disseminate information about Swedish research on the Internet, regardless of where the information exists.
The technological solution behind the system is a search robot which searches for information via the Internet, on various organizations’ servers. The search engine functions much like the well-known search engine Alta Vista. However, the difference lies in the fact that this engine only searches for information on servers belonging to organizations which are members of SAFARI, and is thus based on the principle of shared responsibility. The basic prerequisites for the information provided via the SAFARI search engine is that the information has been published by an approved SAFARI organization and that the information is indexed by the SAFARI model for metadata. The metadata format used is the Dublin Core model embedded in HTML and a classification of the subject according to the CERIF standard established by the European Commission for research information.
The information might be published on an individual researcher’s own web-page or gathered in a database which generates web-pages. Thus, metadata formats and standards facilitate the indexing of already existing web-pages. The Z39.50 protocol is implemented in searching databases. Technological solutions, e.g. in the form of metadata tools and search robots, are being supplied by NetLab at Lund University, using information from projects such as the Nordic Web Index, and DESIRE (the Development of a European Service for Information on Research and Education).
An example of the Dublin Core embedded in HTML
<html>
<head>
<title>Limpopo River : survey data</title>
<link rel = “schema.DC”
href = “http://purl.org/DC/elements/1.0”>
<meta name = “DC.Title”
content = “Limpopo River : survey data”>
<meta name = “DC.Creator”
content = “Shelley, Percy B.”>
<meta name = “DC.Type”
content = “dataset”>
</head>
<body>
The content of the Web-page …
</body></html>
For both decentralised database management systems and distributed
systems, a user-interface with a single point of entry has to be implemented,
through which all systems may be accessed transparently. The interface must
offer functionality according to the system structure, by allowing users to
search, navigate and browse through the various abstraction levels. The user
should view and use the system as if it were a single stand-alone information
system.
Although an information gateway cannot be regarded as intrinsically relevant to the topic ‘integration of databases’, it is important to consider this concept in the broader framework of planning for the accessibility of S&T data in Africa.
In the environment of electronic information, an information gateway represents a single point of entry to a variety of online resources and may include hyperlinks to various online databases and digital archives of data. It refers to a network resource discovery service that provides database(s) of resource descriptions created according to specific selection and quality criteria. (Kirriemuir, et al, 1998). So from one starting point you are presented with a grouping of resources and a connection facility to those resources, which could be based anywhere world-wide. Some information gateways take the form of a subject guide to Internet based resources. Others have a wider range of services offering access to primary and secondary information sources.
The DESIRE Information Gateways handbook describes an Information gateway as quality controlled information services that have the following charateristics:
The integration of data sources from Africa could yield major breakthroughs for interdisciplinary work and indigenous knowledge systems in Africa.
Important factors to take cognisance of are:
The transient nature of information on the Internet is worrying; for example, the URL has no guarantee of permanency. The requirement for long-term commitment to preserving electronic databases should be addressed.
The IT infrastructure for scholarly
and research communication varies from country to country in Africa. Moreover,
Professor Chisenga of the University of Namibia, who delivered a paper at the
65th IFLA Council and General Conference during 1999, has indicated
that the establishment of full Internet access across the African continent
has accelerated swiftly since 1995. In general, academic and research institutions
appear to be at the forefront in using the Internet. Chisenga concludes that
it may be said that the basic infrastructure and an environment conducive
to contributing to the global information culture already exist on the Africa
continent.
DESIRE information gateways handbook. Available at http://www/ukoln.ac.uk/DESIRE/ [referenced 21-06-2000]
Berghahl, B. (1989). IFLA’s Programme Advancement of Librarianship in the Third world ALP: a proposal for the future. Stockholm : Swedish Library Association.
Chisenga, Justin (1999). Global information infrastructure and the question of the African content. Paper delivered at the 65th IFLA Council and General Conference, 20-18 August 1999. Available at http://www.ifla.org/IV/ifla65/papers/118-116e.htm [referenced 6.6.2000]
Dempsey, Lorcan & Heery, Rachel (1997). DESIRE : Development of a European Service for Information on Research and Education. Available at http://www.ukoln.ac.uk/metadata/DESIRE [referenced 6.6.2000]
Dempsey, Lorcan, et al. (1999). International information gateway collaboration : report of the first Imesh Framework Workshop. D-Lib magazine (1999) Dec. Available at: http://www.dlib.org/dlib/december99/12dempsey.html [referenced 15.6.2000]
Electronic Communication and Research in Europe: a conference organised by the Academia Europaea, Darmstadt, 15-17 April 1998. Edited by Jack Meadows and Heinz-Dieter Böcker. Luxembourg : European Communities, c1999. pp. 248.
Hakala, Juha (2000). Dublin Core Metadata Initiative. CRIS2000 Conference, 25-27 May 2000, Espoo, Finland. Available at http://www.cordis.lu/cris2000/ [referenced 21.6.200]
Inter-university Consortium for
Political and Social Research(2000). Data Documentation Initiative : a project
of the social science community. Available at http://www.icpsr.umich.edu/DDI/codebook.html
[referenced 15.6.2000]
Kirriemuir, John, et al. (1998). Cross-searching subject gateways : the query routing and forward knowledge approach. D-Lib magazine(1998) Jan. Available at http://www.dlib.org/dlib/january98/01kirriemuir.html [referenced 15.6.2000]
Kunze, John (1999). Encoding Dublin Core Metadata in HTML. RFC 2731. Internet Engineering Task Force, December 1999. Available at http://www.ietf.org/rfc/rfc2731.txt [referenced 8.6.2000]
Miller, Paul (1999). Z39.50 for all. Available at http://www.ariadne.ac.uk/issue21/z3950/intro.html [referenced 7-09-1999]
Moen, William (1999). The ANSI/NISO Z39.50 protocol : information retrieval in the information infrastructure, Part 1. Available at http://www.lis.nl/engineering/standards/Z39.50/z3950.htm. [referenced 07-09-1999]
Nwalo, KIN (2000). Managing information for development in the 21st century : prospects for African libraries, challenges to the world. Paper delivered at the 66th IFLA Council and General Conference, 13-16 August 1999. Available at http://www.ifla.org/Ivifla66/papers/012-114e.htm [referenced 6.6.2000]
Renato, Iannella (1999). Dublin Core Metadata Initiative : DC agent qualifiers : working draft. Available at http://www.mailbase.ac.uk/lists/dc-agents/files/wd-agent-qual.html [referenced 20.6.2000]
Swedish National Agency for Higher Education (2000). SAFARI disseminating Swedish research on the Internet. Available at http://safari.hsv.se [referenced 6.6.2000]
United States. Federal Geographic Data Committee (2000). ISO Metadata standard register review. Available at http://www/fgdc.gov/whatsnew/whatsnew.html [referenced 14.6.2000]