From Data warehousing to Data Mining
or From Data to Knowledge
Abdourahmane FAYE
LRI - Bat. 490 - Université Paris 11
91400 Orsay – France
faye@lri.fr
http://www.lri.fr/~faye
The past two decades has seen a dramatic increase in the amount of information or data being stored in electronic format. This accumulation of data has taken place at an explosive rate. It has been estimated that the amount of information in the world doubles every 20 months and the size and number of databases are increasing even faster. The increase in use of electronic data gathering devices such as point-of-sale or remote sensing devices has contributed to this explosion of available data. Figure 1 from the Red Brick company illustrates the data explosion.
|
Figure 1: The Growing Base of Data
Data storage became easier as the availability of large amounts of computing power at low cost (i.e. the cost of processing power and storage is falling) made data cheap. There was also the introduction of new methods and technics coming from artificial intelligence and machine learning fields for knowledge representation or extraction, and data analysis in addition to traditional statistical analysis of data. The new methods tend to be computationally intensive hence a demand for more processing power.
Having concentrated so much attention on the accumulation of data, the problem was what to do with this valuable resource?
So, It was noticed that « we are drowning in data, but starving for knowledge ». It was also recognised that information is at the heart of business operations and that decision-makers could make use of the data stored to gain valuable insight into the business. Database Management systems gave access to the data stored but this was only a small part of what could be gained from the data. Traditional on-line transaction processing systems, OLTPs, are good at putting data into databases quickly, safely and efficiently but are not good at delivering meaningful analysis in return. Analysing data can provide further knowledge about a business for example, by going beyond the large amounts of data explicitly stored to derive knowledge about the business. This is where Data Warehousing technologies, integrated with Data Mining (also called Knowledge Discovery in Databases - KDD) systems provide obvious benefits for any enterprise.
Data warehousing is a new information technology architecture for collecting, storing and accessing massive volumes of data with the purpose of driving decision support systems. It is expected to alter the model of industrial production. Traditional database management systems are application-oriented and provide reliable and efficient processing of the operational data in an organization. In recent years, however, organizations have increasingly put the emphasis on subject-oriented applications in which massive volumes of current and historical data are explored and analysed in order to provide support for high-level decision making. This data is coming from various sources that are autonomous, heterogenous and geographically dispersed.
Support for decision making has rapidly grown into a multibillion dollar industry, and the design of systems and tools for decision support is providing new important challenges and research directions.
In this paper, I will briefly introduce the concepts and issues connected with data warehouses, and I will outline some relevant research directions. I will then present Data Mining, and discuss the process of transforming data to knowledge with Data Mining technologies. Then I will present some interesting applications of data warehousing and data mining technologies.
Organizational decision making requires consolidated and comprehensive information on all aspects of an enterprise, drawn from several operational databases maintained by different business units, or from external sources accessed through the internet. Of course, such information can be obtained by simply querying the operational databases or the external sources, in the traditional way. However, this way of obtaining information presents several disadvantages, with regard to decision making:
The need to overcome these shortcomings of the traditional approach led to the concept of data warehouse. In fact, what the data warehouse represents is a recognition that the characteristics and usage patterns of operational systems which are used to automate business processes and the characteristics of decision support systems are fundamentally different - although linked together.
The warehousing approach consists of collecting, integrating and storing in advance all information needed for decision making, so that this information is available for direct querying and analysis. So its key idea is to collect data in advance of queries.
The data warehouse is a subject-oriented corporate database which deals with the problem of having multiple data models implemented on multiple platforms and architectures in the entreprise. What many corporate computer users understand is that the key to identifying corporate threats and opportunities lies in the corporate data which is often embedded in legacy systems on obsolescent technologies, and they realize that the businesses needs to get at that data today. Many of the same issues that are addressed in distributed databases are also applicable to data warehouses.
The corporate data warehouse may be defined in terms of six key characteristics that differentiate the data warehouse from other database systems in the enterprise. The data in the data warehouse is:
So, a data warehouse is a
Ø subject-oriented
Ø integrated
Ø time-variant
Ø nonvolatile
collection of data in support of management's decisions.
The data warehouse is mainly differentiated from an operational database in the following aspects.
Ø Data in the data warehouse is stored primarily for the purpose of providing data that can be interrogated by business people to gain value from the information derived from daily operations.
Ø The use of the data warehouse is to drive decision support.
Ø The operational database is used to process information that is needed for the purposes of performing operational tasks.
Ø The operational database is active for updates during all hours that business activities are executed, whereas the data warehouse is used for read only querying during active business hours.
Table 1 resumes the differences between warehouses and traditional databases [HANKAMB].
|
Feature |
Traditional Database |
Warehouse |
|
Characteristic |
Operational processing |
Informational processing |
|
Orientation |
Transaction |
Analysis |
|
User |
Database administrators (DBA), clerk, database professional |
Knowledge workers (e.g. managers, executive, analyst) |
|
Function |
Day-to-day operations |
Long term informational requirements, decision support |
|
Database design |
E/R based, application-oriented |
Star/snowflake, subject-oriented |
|
Data |
Current data ; guaranteed up-to-date |
Historical data ; accuracy mantained over time |
|
Summarization |
Primitive, highly detailed |
Summarized, consolidated |
|
View of data |
Detailed, flat relational |
Summarized, multidimentional |
|
Unit of work |
Short, simple transactions |
Complex and long queries |
|
Acces |
Read/write, mostly updates |
Mostly reads |
|
Focus |
Data in |
Information out |
|
Operations |
Index/hash on primary key |
Lots of scans |
|
Number of records accessed |
Tens |
Millions |
|
Number of users |
Thousands |
Hundreds |
|
Database size |
100 MB to GB |
100 GB to TB |
|
Priority |
High performance, high availability |
High flexibility, end-user autonomy |
|
Metric |
Transaction throughput |
Query throughput, response time |
Table 1 : Comparison between traditional databases and data warehouses.
The trend towards data warehousing is complemented by the development of powerful analysis tools. Three broad classes of such tools have emerged:
Ø Relational systems that are designed to support complex SQL-type queries efficiently.
Ø Systems that provide efficient support for queries involving group-by and aggregation operators, used in On-Line Analytical Processing (OLAP).
Ø Tools for exploratory data analysis, or data mining, in which a user looks for interesting patterns in the data.
Figure 2 presents the global architecture of a data warehouse system.
Clearly, evaluating OLAP or data mining queries over data sources that are autonomous, heterogeneous and geographically dispersed is likely to be extremely slow. However, for such complex analysis, often statistical in nature, it is not essential that the most current version of the data be used. Thus the natural solution is to create a centralized repository of all the required data, that is, a data warehouse. The availability of a data warehouse facilitates the application of OLAP and data mining tools, and conversely, the desire to apply such analysis tools is a strong motivation for building a data warehouse.
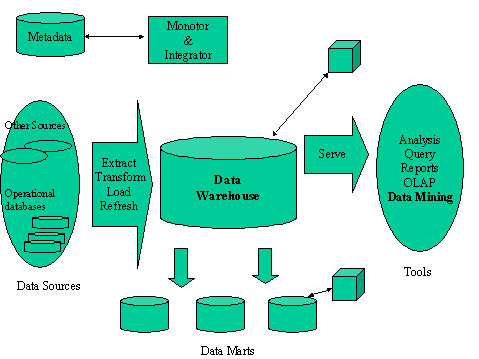 |
Figure 2 : Data Warehouse Architecture
The development of data warehousing technologies provides to database professional and decision makers clean and integrated data that is already transformed and summarized, therefore making it an appropriate environment for more efficient decision support systems (DSS) and entreprise information systems (EIS) applications, such as Data Mining or Olap systems (Figure 2).
The term data mining has been stretched beyond its limits to apply to any form of data analysis. Some of the numerous definitions of Data Mining, or Knowledge Discovery in Databases (named KDD) are:
Ø Data Mining, or Knowledge Discovery in Databases (KDD) as it is also known, is the nontrivial extraction of implicit, previously unknown, and potentially useful information from data. This encompasses a number of different technical approaches, such as clustering, data summarization, learning classification rules, finding dependency net works, analysing changes, and detecting anomalies [FPSU].
Ø Data mining is the search for relationships and global patterns that exist in large databases but are `hidden' among the vast amount of data, such as a relationship between patient data and their medical diagnosis. These relationships represent valuable knowledge about the database and the objects in the database and, if the database is a faithful mirror, of the real world registered by the database.
Ø Data mining refers to "using a variety of techniques to identify nuggets of information or decision-making knowledge in bodies of data, and extracting these in such a way that they can be put to use in the areas such as decision support, prediction, forecasting and estimation. The data is often voluminous, but as it stands of low value as no direct use can be made of it; it is the hidden information in the data that is useful".
Basically data mining is concerned with the analysis of data and the use of software techniques for finding patterns and regularities in sets of data. It is the computer which is responsible for finding the patterns by identifying the underlying rules and features in the data. The idea is that it is possible to strike gold in unexpected places as the data mining software extracts patterns not previously discernable or so obvious that no-one has noticed them before.
Data mining analysis tends to work from the data up and the best techniques are those developed with an orientation towards large volumes of data, making use of as much of the collected data as possible to arrive at reliable conclusions and decisions. The analysis process starts with a set of data, uses a methodology to develop an optimal representation of the structure of the data during which time knowledge is acquired. Once knowledge has been acquired this can be extended to larger sets of data working on the assumption that the larger data set has a structure similar to the sample data. Again this is analogous to a mining operation where large amounts of low grade materials are sifted through in order to find something of value.
The following diagram (Figure 3) summarises the some of the stages/processes identified in data mining and knowledge discovery [FPSU].
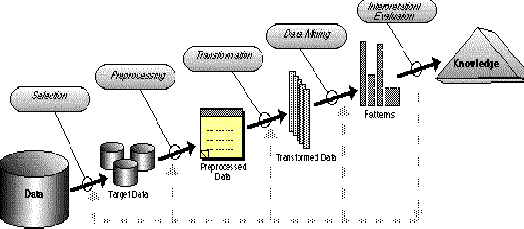 |
Figure 3 : Steps of a KDD process
The phases depicted start with the raw data and finish with the extracted knowledge which was acquired as a result of the following stages:
· Selection - selecting or segmenting the data according to some criteria e.g. all those people who own a car, in this way subsets of the data can be determined.
· Preprocessing - this is the data cleansing stage where certain information is removed which is deemed unnecessary and may slow down queries for example unnecessary to note the sex of a patient when studying pregnancy. Also the data is reconfigured to ensure a consistent format as there is a possibility of inconsistent formats because the data is drawn from several sources e.g. sex may recorded as f or m and also as 1 or 0.
· Transformation - the data is not merely transferred across but transformed in that overlays may added such as the demographic overlays commonly used in market research. The data is made useable and navigable.
· Data mining - this stage is concerned with the extraction of patterns from the data. A pattern can be defined as given a set of facts(data) F, a language L, and some measure of certainty C a pattern is a statement S in L that describes relationships among a subset Fs of F with a certainty c such that S is simpler in some sense than the enumeration of all the facts in Fs.
The discovered patterns in this step can have a particular representational form or a set of such reprentations : classification rules or trees, regressions, clustering, and so forth.
· Interpretation and evaluation - the patterns identified by the system are interpreted into knowledge which can then be used to support human decision-making e.g. prediction and classification tasks, summarizing the contents of a database or explaining observed phenomena.
As shown in Figure 3, Data Mining is indeed just a step, an essential one, of the whole process of knowledge discovery.
We also note that the KDD process can involve significant iterations and may contain loops between any two steps.
This Figure also shows that KDD can be considered as the process of transforming data (first step) to knowledge (end step).
In general, data mining tasks can be classified into two categories : descriptive and predictive data mining. The former describes the data set in a concise and summary manner and presents interesting general properties of the data ; whereas the latter constructs one or a set of models, performs inference on the available set of data, and attempts to predict the behavior of new data sets.
A data mining system may accomplish one or more of the following data mining tasks [FPSU] :
Ø Class description : class description provides a concise and succint summarization of a collection of data and distinguishes it from others. The summarization of a collection of data is called class characterization ; whereas the comparison between two or more collections of data is called class comparison or discrimination. Class description should cover not only its summary properties, such as count, sum, and average, but also its properties on data dispersion, such as variance, quartiles, etc…
For example, class description can be used to compare European versus Asian sales of a company, identify the important factors which discriminate the two classes, and present a summarized overview.
Ø Association : Association is the discovery of association relationships or correlations among a set of items. They are often expressed in the rule form showing attribute-value conditions that occur frequently together in a given set set of data. An association rule in the form of X Þ Y is interpreted as « database tuples that satisfy X are likely to stisfy Y ». Association analysis is widely used in transaction data analysis for directed marketing, catalog disign and other business decision making process.
Substancial research has been performed recently on association analysis with efficient algorithms proposed, including the level-wise apriori search, mining multiple level, multidimensional association, mining associations for numerical categorical and interval data, meta-pattern directed rule constraint-base mining, and mining correlations.
Ø Classification : classification analyses a set of training data (i.e. a set of objects whose class level is known) and construct a model for each class base on the futures on the data. A decision tree or a set of classification rules is generated by such a classification process, wich can be used for better understanding of each class in the database and for classification of future data. For example, one may classify desseases and help predict the kind of desseases based on the symptoms of patients.
They have been many classification methods developped in the fields of machine learning, statistics, database, neural network, rough sets, and others. Classification have been used in customer segmentation, business modeling, and credit analysis.
Ø Prediction : this mining function predicts the possible values of some missing data or the value distribution of certain attributes in a set of objects. It involves the finding of the set of attributes relevant to the attribute of interest (e.g. by some statistical nalysis) and predicting the value distribution based on the set of data similar to the selected object (s). For example, an employee’s potential salary can be predicted based on the salary distribution of similar empoyees in the company. Usually, regrassion analysis, generalised linear model, correlation analysis and decision trees are useful tools in quality prediction. Genetic algorithms and neural network models are also popularly used in prediction.
Ø Custering : Cluster analysis is to identify clusters embedded in the data, where a cluster is a collection of data objetcs « similar » to one another. Similarity can be expressed by distance functions specified by users or experts. A good clustering method high quality clusters to ensure that the inter-cluster similarity is low and the intra cluster similarity is high. For example, one may cluster the houses in an area according to their house category, floor area, and geographical locations.
Data minignresearch has been focused on high quality and scalable clustering methods for large databases and multidimensional data warehouses.
Ø Time-series analysis : Time-series analysis is to analyze large set of time-series data to find certain regularities and interesting characteristics, including serach for similar sequences or subsequences, and mining sequential patterns, periodicities, trends and deviations. For example, one may predict the trend of the stock values for a company based on its stock history, business situation, competitors’ performance, and current market.
There are also other data mining tasks, such as outlier analysis, etc….Indentification of new data mining tasks to make better use of the collected data itself is an interesting research topic.
Data mining is an interdisciplinary field, drawing from areas such as database systems, data warehousing, statistics, machine learning, data visualization, information retrieval, inductive learning and high performance computing. Other contributing areas include neural networks, pattern recognition, spatial data analysis, image databases, signal processing, probabilistic graph theory, and inductive logic programming. Data mining needs the integration of approaches from multiple disciplines.
We briefly present in this section some of these approaches.
Induction is the inference of information from data and inductive learning is the model building process where the environment i.e. database is analysed with a view to finding patterns. Similar objects are grouped in classes and rules formulated whereby it is possible to predict the class of unseen objects. This process of classification identifies classes such that each class has a unique pattern of values which forms the class description. The nature of the environment is dynamic hence the model must be adaptive i.e. should be able learn.
Generally it is only possible to use a small number of properties to characterise objects so we make abstractions in that objects which satisfy the same subset of properties are mapped to the same internal representation.
Inductive learning where the system infers knowledge itself from observing its environment has two main strategies:
· supervised learning - this is learning from examples where a teacher helps the system construct a model by defining classes and supplying examples of each class. The system has to find a description of each class i.e. the common properties in the examples. Once the description has been formulated the description and the class form a classification rule which can be used to predict the class of previously unseen objects. This is similar to discriminate analysis as in statistics.
· unsupervised learning - this is learning from observation and discovery. The data mine system is supplied with objects but no classes are defined so it has to observe the examples and recognise patterns (i.e. class description) by itself. This system results in a set of class descriptions, one for each class discovered in the environment. Again this similar to cluster analysis as in statistics.
Induction is therefore the extraction of patterns. The quality of the model produced by inductive learning methods is such that the model could be used to predict the outcome of future situations in other words not only for states encountered but rather for unseen states that could occur. The problem is that most environments have different states, i.e. changes within, and it is not always possible to verify a model by checking it for all possible situations.
Given a set of examples the system can construct multiple models some of which will be simpler than others. The simpler models are more likely to be correct if we adhere to Ockhams razor, which states that if there are multiple explanations for a particular phenomena it makes sense to choose the simplest because it is more likely to capture the nature of the phenomenon.
Many data analysis technics have been developped in statistics over many years of studies, related to classification and induction problems.
Statistics has a solid theoretical foundation but the results from statistics can be overwhelming and difficult to interpret as they require user guidance as to where and how to analyse the data. Data mining however allows the expert's knowledge of the data and the advanced analysis techniques of the computer to work together.
Statistical analysis systems such as SAS and SPSS have been used by analysts to detect unusual patterns and explain patterns using statistical models such as linear models. Statistics have a role to play and data mining will not replace such analyses but rather they can act upon more directed analyses based on the results of data mining. For example statistical induction is something like the average rate of failure of machines.
Machine learning is the automation of a learning process and learning is tantamount to the construction of rules based on observations of environmental states and transitions. This is a broad field which includes not only learning from examples, but also reinforcement learning, learning with teacher, etc. A learning algorithm takes the data set and its accompanying information as input and returns a statement e.g. a concept representing the results of learning as output. Machine learning examines previous examples and their outcomes and learns how to reproduce these and make generalisations about new cases.
Generally a machine learning system does not use single observations of its environment but an entire finite set called the training set at once. This set contains examples i.e. observations coded in some machine readable form. The training set is finite hence not all concepts can be learned exactly.
A large set of data analysis methods have been developped in other research fields. Neural networks have shown its effectiveness in classification, prediction , and clustering analysis tasks. However, with increasingly large amounts of data stored in databases and data warehouses for data mining, these methods face challenges on efficiency and scalability. Effic ient data structures, indexing and data accessing techniques developped in database researches contribute to high performance data mining. Many data analysis methods developed in statistics, machine learning, and other disciplines need to be re-examined, and set-oriented , scalable algorithms should be developped for effective data mining.
Another difference between traditional data analysis and data mining is that traditional data analysis is assumption-driven in the sense that a hypothesis is formed and validated against the data, whereas data mining in contrast is discovery driven in the sense that patterns are automatically extracted from data, which requires substancial efforts. Therefore, high performance computing wil play an important role in data mining.
Parallel, distributed, and incremental data mining methods should be developed, and parallel computer architectures and other high performance computing techniques should be explored in data mining as well.
Since it is easy for human eyes to identify patterns and regularities in data sets or data mining results, data and knowledge visualization is an effective approach for presentation of data and knowledge, exploratory data analysis, and iterative data mining.
With the construction of large data warehouses, data mining in data warehouse is one step beyond on-line analytic processing (OLAP) of data warehouse data. By integration with OLAP and data cubes technologies, on-line analysticakl mining mechanism contributes to interactive mining of multiple abstraction spaces of data cubes.
Data mining has many and varied fields of application some of which are listed below.
Ø Retail/Marketing
Ø Banking
Ø Insurance and Health Care
Ø Transportation
Ø Medicine
The data warehouse and data mining concepts have now been widely accepted by virtually all of the leading hardware and software vendors, but it is still immature in the sense that there is no integrated
product set available today for these two technologies. This is because there are still several technical problems that must be overcome before useful data warehouse products can be developped. The need
to overcome these problems is driving current research efforts, and in this section we outline some of the emerging research lines.
Concerning data warehousing, current research concerns mainly the extraction of data from operational databases or external sources, their integration into the warehouse, and various aspects related to warehouse specification and performance improvements (see Figure 2).
Ø Data Extraction :
The basic problem here is the translation of the underlying information into the format of the data model used by the warehousing system. A component that translates an information source into a common integrating model is called a translator or wrapper [C94, W92].
Another problem in data extraction is update detection, i.e. monitoring the information source for changes to the data that are relevant to the warehouse, and propagating those changes to the integrator (after translation). Depending on the facilities that provide for update detection, the information sources can be classified into several types [Widom95], so that notification of changes of interest can be programmed to occur automatically. Each of these types of information sources provides particular research problems for update detection.
Clearly, the functionality of a wrapper/monitor component depends on the type of the source, and on the data model used by the source. Therefore, developping techniques that automate the process of implementing wrapper/monitor components is an important research problem.
Ø Data Integration :
The task of the integrator is to receive update notifications from the wrapper/monitors and reflect these updates in the data warehouse. Now, the data in the warehouse can be seen as a set of materialised views, and thus the task of the integrator can be seen as materialised view maintenance [GM95].
However, there are two reasons why conventional techniques cannot be applied directly here, each giving rise to interesting research problems.
The first reason is that warehouse views are often more complicated than usual views of relational systems, and may not be expressible using standard languages, such as SQL. For example, typical warehouse views may contain historical data or highly aggregated and summarized information, while the underlying sources may not contain such information. So relevant areas of research here include temporal databases [S91], and efficient view maintenace in the presence of aggregate and summary information [C92].
The second reason why conventional techniques cannot be applied directly here is that the base relations of the warehouse views reside at the information sources (and not in the warehouse). As a result, the system maintaining the warehouse views (the integrator) is only loosely coupled with the systems maintaining the base data (the information sources). In fact, the underlying information sources simply report changes but do not participate in warehouse views maintenance. In this context, keeping the warehouse views consistent with the base data is a difficult problem, and sophisticated algorithms must be used for view maintenance.
Ø Warehouse Specification :
Although the design of integrators can be based on the data model used by the warehouse, a different integrator is still needed for each warehouse, since each warehouse contains a different set of views over different base data. As with wrappers/monitors, it is desirable to provide techniques for generating integrators from high-level non-procedural specifications. In an ideal architecture, the contents of the warehouse are specified as a set of view definitions, from which the warehouse updating tasks performed by the integrator and the update detection tasks required of the wrapper/monitors are deduced automatically. This approach is actually pursued by the WHIPS data warehousing project [HG95].
Ø Performance Improvements :
Warehouse maintenance can be improved in several ways, most of them related to the way updates are propagated from the information sources to the warehouse views. For example, determining when an update of base data leaves the warehouse views unchanged is an important issue (see [LS93] for work in this direction).
An interesting problem arising in this context is the so-called self-maintainability of the warehouse. When an update occurs to base data, in order to reflect the changes into the warehouse views, the integrator may need additional data from the underlying information sources. However, issuing queries to the information sources can cause various problems, such as delays in response time, high cost for the query, or various anomalies in the warehouse maintenance [ZGHW95]. Additionnally, some of the information sources may not accept ad-hoc queries (e.g legacy systems). In this context, an interesting research problem is how to maintain the warehouse consistent with the sources, based on the reported changes at the sources alone. In view maintenance, when additional queries over base data are never required to maintain a given view, the view is said to be self maintainable [BCL89].
In general, in order to make a warehouse self-maintainable, we need to store a set of "auxiliary" views, in addition to the warehouse views. The problem of identifying these auxiliary views seems to have been considered first in [QGMW96]. The approach followed in [QGMW96] is to first determine the maintainance expressions (assuming a single view in the warehouse) and then to proceed in either of two different ways:
t Extract the auxiliary views from the maintenance expressions.
t Guess a set of auxiliary views, check if the maintenance expressions can be computed from the warehouse view and the auxiliary views, and check whether the auxiliary views can be maintained from the warehouse.
A sort of "opposite" approach to that of [QGMW96] is reported in [LLSV98], where the set of auxiliary views is determined first (using the definitions of the warehouse views) and then maintenance expressions are derived for the warehouse views as well as for the auxiliary views.
We note that there may be more than one set of auxiliary views that make the warehouse self-maintainable. Determining such a set, which at the same time is "minimal", seems to be an open problem.
Ø Query optimization :
Another research area of importance to the continued growth of this technology is that of query optimization.
It is possible that a query may have to access millions or even billions of records and may involve computationally complex operations such as joins and/or nested subqueries. In these cases, the system must be able to respond in a manner appropriate to the application for which it was designed. Many times, the response time is critical to the success or failure of a system based not on failure from a technical standpoint (i.e. the query correctly returned the desired data) but from a business standpoint (i.e. the data took two days to arrive). Current access methods need to
be improved for applications which require computationally expensive operations on a regular basis. Some areas explored in current research have been on bit map indexing to improve the response time significantly, but much work is still to be done to improve indexing methods to speed up operations on data warehouses.
Ø The Importance of User Interfaces :
Another area that I feel needs to be addressed in the data warehouse model is that of user friendly interfaces to the data. Since one of the requirements of a data warehouse is that they be accessible to users who have a limited knowledge of computer systems or data structures, it is imperative that graphical, self-explaining tools that provide easy access to the warehouse, with little or no training, be available to the users when the system is deployed. It should not be the case that users need to know how to form complex structured queries in order for them to access the desired information.
Little attention has been given to this area, but I feel that if the warehouse concept is to be widely accepted, more tools need to be implemented in order to make the effort required to get decision makers on board be minimized because of the time constraints placed on those people who are in decision making roles.
Concerning data mining, there have been many systems developed in recent years, and this trend of research and development on data mining is expected to be flourishing because the huge amounts of data have been collected in databasese and data warehouses, and the necessity of understanding and making good use of such data in decision making has served as the driving force in data mining.
The main problems that arise are related to the fact that databases tend be dynamic, incomplete, noisy, and large. Other problems arise as a result of the adequacy and relevance of the information stored.
Ø Limited Information
A database is often designed for purposes different from data mining and sometimes the properties or attributes that would simplify the learning task are not present nor can they be requested from the real world. Inconclusive data causes problems because if some attributes essential to knowledge about the application domain are not present in the data it may be impossible to discover significant knowledge about a given domain. For example one cannot diagnose malaria from a patient database if that database does not contain the patients red blood cell count.
Ø Noise and missing values
Databases are usually contaminated by errors so it cannot be assumed that the data they contain is entirely correct. Attributes which rely on subjective or measurement judgements can give rise to errors such that some examples may even be mis-classified. Error in either the values of attributes or class information are known as noise. Obviously where possible it is desirable to eliminate noise from the classification information as this affects the overall accuracy of the generated rules.
Missing data can be treated by discovery systems in a number of ways such as;
Noisy data in the sense of being imprecise is characteristic of all data collection and typically fit a regular statistical distribution such as Gaussian while wrong values are data entry errors. Statistical methods can treat problems of noisy data, and separate different types of noise.
Ø Uncertainty
Uncertainty refers to the severity of the error and the degree of noise in the data. Data precision is an important consideration in a discovery system.
Ø Size, updates, and irrelevant fields
Databases tend to be large and dynamic in that their contents are ever-changing as information is added, modified or removed. The problem with this from the data mining perspective is how to ensure that the rules are up-to-date and consistent with the most current information. Also the learning system has to be time-sensitive as some data values vary over time and the discovery system is affected by the `timeliness' of the data.
Another issue is the relevance or irrelevance of the fields in the database to the current focus of discovery for example post codes are fundamental to any studies trying to establish a geographical connection to an item of interest such as the sales of a product.
The diversity of data, data mining tasks, and data mining approaches poses many other challenging research issues on data mining. The design of data mining langages, the development of efficient and effective data mining methods and systems, the construction of interactive and integrated data mining environment, and the application of data mining techniques at solving large application problems are the important tasks for data mining researchers and data mining system and application developers.
Moreover, with the fast computerization of the society, the social impact of data mining should not be under-estimated. When a large amount of interrelated data are effectively analyzed from different perspectives, it can pose threats to the goal of protecting data security and guarding against the invasion of privacy. It is a challenging task to develop effective techniques for preventing the disclosure of sensitive information in data mining, especially as the use of data mining systems is rapidly increasing in domains ranging from business analysis, customer analysis, to medicine and government.
Data warehouses were introduced with the purpose of providing support for decision making,
through the use of such tools as On-Line Analytical Processing and Data Mining. The data stored in a warehouse comes from autonomous, heterogeneous and geographically dispersed information sources. Therefore, the warehousing approach consists of collecting, integrating, and storing in advance all information needed for decision making, so that this information is available for direct querying, data mining and other analysis. So the process of data mining aims at transforming the amount of data stored in data warehouses repositories to knowledge.
The data warehouse and data mining concepts have received much attention recently by both the database industry and the database research community. This is because data warehouses will provide a means for querying huge amounts of data that was accumulated in the past, but never utilized for anything useful.
Data warehouses differ from traditional databases in that they are much larger in size, they store not only current data but also historical data or highly aggregated and summarized information, and they have different workloads. These differences require particular design and implementation techniques, and pose new research problems, as for data mining, some of which were outlined in the present paper.
Bibliography
[AASY97] D. Agrawal, A. El Abbadi, A. Singh, T. Yurek, ``Efficient View Maintenance at Data Warehouses,'' Proc.\ ACM SIGMOD 1997, 417--427.
[DWDMO] A. Berson, S. J. Smith,``Data Warehousing, Data Mining, and OLAP'', Mc Graw Hill, 1997
[BL] M. J.A. Berry, G. Linoff « Data Mining Techniques for Marketing, Sales, and Customer Support». John Wiley & Sons, Inc. Wiley Computer Publishing, 1997.
[BCL89] J.A. Blakeley, N. Coburn, P. Larson, ``Updating derived relations: Detecting irrelevant and autonomously computable updates,'' ACM TODS 1989, 14 (3), 369--400.
[BLT86] J.A. Blakeley, P. Larson, F.W. Tompa, ``Efficiently Updating Materialized Views,'' Proc. ACM SIGMOD 1986, 61--71.
[CW91] S. Ceri, J. Widom, ``Deriving Production Rules for Incremental View Maintenance,'' Proc. 17th VLDB 1991, 108--119.
[CD97] S. Chaudhuri, U. Dayal, ``An Overview of Data Warehousing and OLAP Technologies,'' Proc. ACM SIGMOD 1997, 65--74.
[CKPS95] S. Chaudhuri, R. Krishnamurthy, S. Potamianos, K. Shim, ``Optimizing Queries with Materialized Views,'' Proc. 11th ICDE 1995, 190--200.
[C94] S. Chawathe and als, "The Tsimmis project: an integration of heterogenous information sources". In Proceedings of 100th Anniversary Meeting of the information Processing Society of Japan, p.7-18, Tokyo, Japan, Oct. 1994.
[C92] J. Chomicky. "History-less checking of dynamic integrity constraints". In Proceedings of the eight International Conference on data Engineering, p. 557-564, Phoenix, Arizona, February 1992.
[FPSU] U. M. Fayyad, G. Piatestsky-Shapiro, P. Smyth, R. Uthurusamy « Advances in Knowledge Discovery and Data Mining », AAAI Press/ The MIT Press,1996
[GB95] A. Gupta, J.A. Blakeley, ``Using partial information to update materialized views,'' Information Systems 1995, 20 (8), 641--662.
[GJM94] A. Gupta, H.V. Jagadish, I.S. Mumick, ``Data Integration using Self-Maintainable Views,'' Technical Memorandum, AT\&T Bell Laboratories, November 1994.
[GM95] A. Gupta, I.S. Mumick, ``Maintenance of Materialized Views: Problems, Techniques, and Applications,'' IEEE Data Engineering Bulletin 1995, 18 (2), 3--18.
[GMS93] A. Gupta, I.S. Mumick, V.S. Subrahmanian, ``Maintaining Views Incrementally,'' Proc.ACM SIGMOD 1993, 157--167.
[HG95] J. Hammer, H. Garcia-Molina, J. Widom, W. Labio, and Y. Zhuge. ``The Stanford Data Warehousing Project''. IEEE Data Engineering Bulletin, Special Issue on Materialized Views and Data warehousing, 18(2):41-48, June 1995.
[HANKAMB] J. Han , M. Kamber « Data Mining : Concepts and Techniques », Morgan Kaufmann Publishers, 2000.
[Huy97] N. Huyn, ``Multiple-View Self-Maintenance in Data Warehousing Environments'', Proc. 23rd VLDB 1997, 26--35.
[Inm96] W.H. Inmon, Building the Data Warehouse, John Wiley Sons, 2nd ed., 1996
[KLM97] A. Kawaguchi, D. Lieuwen. I.S. Mumick, D. Quass, K.A. Ross, ``Concurrency Control Theory for Deferred Materialized View,'' Proc. 6th ICDT 1997, Springer LNCS 1186, 306--320.
[LLSV98] D. Laurent, J. Lechtenbörger, N. Spyratos, G. Vossen, ``Using Complements to Make Data Warehouses Self-Maintainable w.r.t. Queries and Updates,'' IEEE Intl. Conference on Data Engineering, Sydney, Australia, March 1999.
[LS93] A. Levy, Y. sagiv. « Queries independant of updates », in Proceedings of the Nineteenth International Conference on Very Large Data Bases, p. 171-181, Dublin, Ireland, August 1993.
[QGMW96] D. Quass, A. Gupta, I.S. Mumick, J. Widom, ``Making Views Self-Maintainable for Data Warehousing,'' Proc. PDIS 1996.
[QW97] D. Quass, J. Widom, ``On-Line Warehouse View Maintenance,'' Proc. ACM SIGMOD 1997, 393--404.
[SI84] O. Shmueli, A. Itai, ``Maintenance of Views,'' Proc. ACM SIGMOD 1984, 240--255.
[Shu97] H. Shu, ``View Maintenance Using Conditional Tables,'' Proc. 5th DOOD 1997, Springer LNCS 1341, 67--84.
[S91] M.D. Soo. Bibliography of temporal databases. Sigmod Record, 20(1):14-24, March 1991.
[StJ96] M. Staudt, M. Jarke, ``Incremental Maintenance of Externally Materialized Views,'' Proc. 22nd VLDB 1996, 75--86.
[W95] J. Widom, ed., « Special Issue on Materialized Views and Data Warehousing », Data Engineering Bulletin 18 (2) 1995.
[Widom95] J. Widom, ``Research Problems in Data Warehousing,'' Proc. 4th CIKM 1995.
[W92] G. Wiederhold. Mediators in the architecture of future information systems. IEE Computer, 25(3): 38-49, March 1992
[ZGHW95] Y. Zhuge, H. Garcia-Molina, J. Hammer, J. Widom, ``View Maintenance in a Warehousing Environment,'' Proc. ACM SIGMOD 1995, 316--327.
[ZGW97] Y. Zhuge, H. Garcia-Molina, J.L. Wiener, ``Consistency Algorithms for Multi-Source Warehouse View Maintenance,'' Proc. ICDE 1997, 289--300.